Solution Brief
The Triple-FPGA 7130 E-Series:
Optimized for Ultra-low Latency, Inter-FPGA Communication
An Introduction to the Arista 7130 E-Series
The Arista 7130 E-Series supports three Xilinx UltraScale™+ VU9P FPGAs in a one rack unit (RU) form factor. The UltraScale™+ series from Xilinx used in the 7130E devices are a significant step forward from previous solutions.Key improvements over previous Arista 7130 devices include:
- Three times as many logic cells
- Eight times as many DSP slices
- Six times as much memory
- Significantly lower-latency Ethernet transceivers
- The ability for logic to be clocked higher than ever
- Significantly more IO bandwidth
- All the above while consuming less power than the previous generation
When ordered with three FPGA's, there are multiple dedicated communication paths between the FPGAs and the Ethernet network offering flexibility and the ability to optimize communication latency. The characteristics described below refer to the 7130-48E variant (i.e.: 48ports, 1 RU device with 3 Ultrascale + FPGAs).
Network Connectivity
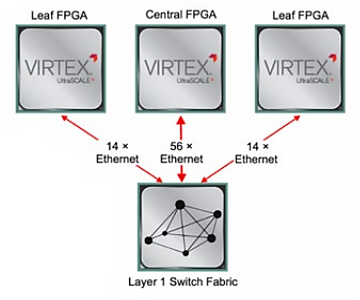 The "Central" FPGA is connected to the Layer 1 switch fabric with 56 Ethernet transceivers. Each "Leaf" FPGA is connected to the Layer 1 switch fabric with 14 Ethernet transceivers. The Layer 1 switch fabric is also connected to the frontpanel ports of the device for external connectivity. This Ethernet connectivity provides enormous flexibility in communication between the FPGAs and the external network.
The "Central" FPGA is connected to the Layer 1 switch fabric with 56 Ethernet transceivers. Each "Leaf" FPGA is connected to the Layer 1 switch fabric with 14 Ethernet transceivers. The Layer 1 switch fabric is also connected to the frontpanel ports of the device for external connectivity. This Ethernet connectivity provides enormous flexibility in communication between the FPGAs and the external network.Moreover, the Layer 1 switch can replicate data from incoming ports to multiple destination ports. For example, incoming UDP/IP multicast data coming into the Layer 1 switch from the network can be delivered to multiple transceivers (if desired) on one, two or all FPGAs in ~3 ns. One or multiple links can be configured between the FPGAs' ports in any required combination. Any of the FPGAs can therefore communicate with each other, or any of the frontpanel ports via an Ethernet interface with a latency of ~50 ns (depending upon which MAC + PHY is used).
The 7130 E-Series Parallel Bus (MMP)
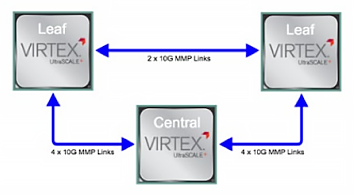 The 7130 E-Series parallel bus is a bus leveraging a large number of parallel IOs. Arista has released the Parallel Bus IP cores package allowing client applications to communicate between FPGAs with the absolute minimum of latency. The first IP core offers a unidirectional bandwidth of 10 Gbps per link and provides an AXI4-stream interface.
The 7130 E-Series parallel bus is a bus leveraging a large number of parallel IOs. Arista has released the Parallel Bus IP cores package allowing client applications to communicate between FPGAs with the absolute minimum of latency. The first IP core offers a unidirectional bandwidth of 10 Gbps per link and provides an AXI4-stream interface.There are four links connecting each Leaf FPGA to the Central FPGA and two links connecting the two Leaf FPGAs together. The direction of each parallel bus link can be configured individually. The key advantage that the parallel bus offers over Ethernet is that, being a parallel rather than a serial bus, its latency is significantly lower. The 7130 Series parallel bus offers one-way transfer latencies between FPGAs of ~8 ns.
Inter-FPGA Communication Latencies Compared
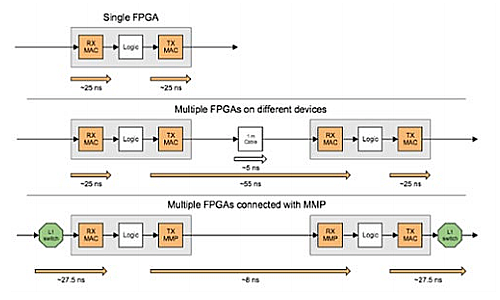
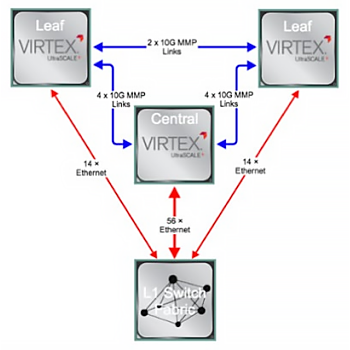 The visual latency breakdown below illustrates the latency differences (also refer to the graphic to the right) compared to a single FPGA reference. The latency benefits of inter-FPGA communication via parallel bus are significant in comparison to Ethernet.
The visual latency breakdown below illustrates the latency differences (also refer to the graphic to the right) compared to a single FPGA reference. The latency benefits of inter-FPGA communication via parallel bus are significant in comparison to Ethernet. In the following example, the latency savings of having FPGAs communicate locally via parallel bus links (~8 ns) versus having FPGAs on different devices communicating via 10GbE (~55 ns) are substantial. The parallel bus offers an 85% latency reduction compared to 10GbE.
What About PCI Express?
Plugging an FPGA PCI Express board into a server remains popular. The rationale is sound; software running on the server's CPUs has an efficient, low-latency path with which to communicate with the FPGA. This rationale however is predicated on the communication between the host application and the FPGA being latency-critical, otherwise why not simply use Ethernet to communicate between the host and CPU?Architecturally, this may be due to a lack of FPGA capacity. It is not always possible to run all the latency-critical code on the FPGA, with part of it having to run on the host. The current generation of Xilinx UltraScale™/UltraScale™+ FPGAs now has sufficient capacity to implement, in many cases, the entirety of the latency-critical portion of a transaction on the FPGA (or FPGAs in the case of the 7130 E-Series).
The non-latency sensitive part of the trade can still reside on the server but now communicate with FPGAs over the Ethernet network with a significantly simpler interface. There is also the added benefit that all communication between the FPGA and the controlling host can be monitored and timestamped as it traverses the network. This can be extremely useful to meet requirements such as record-keeping and compliance.
Example Use-Cases for the Triple-FPGA 7130 E-Series in Electronic Trading
- One "stable" FPGA trading image can be retained with the remaining two FPGAs available for proving out strategies or experimentation.
- Risk checks can be run on a different FPGA from the actual trading algorithms while communicating with significantly lower latency than previously possible.
- Higher FPGA density means that multiple trading strategies can be implemented in as little as 1 RU, with the option to segregate them across three FPGA images.
- Three FPGAs contain over 1 Gb of on-chip RAM which is a real alternative to externally connected QDR-II/QDR-II+ (using the Xilinx UltraScale™+ VU9P as an example).
Summary
- The Arista 7130E Series offers a 1RU device containing three Xilinx UltraScale™ + FPGAs.
- The 7130E devices offer the same enterprise-grade management and core features offered by all Arista devices.
- All three FPGAs are connected to the device's Layer 1 Ethernet switch
- The FPGAs are connected to each other via one (leaf-to-leaf) or two (leaf-to-centre) parallel bus links offering applications inter-FPGA communication in ~8 ns.
- In an electronic trading use case benefiting from multiple-FPGAs, the 7130E Series offers significantly lower latency communication between FPGAs than Ethernet-connected FPGAs.
Copyright © 2019 Arista Networks, Inc. All rights reserved. CloudVision, and EOS are registered trademarks and Arista Networks is a trademark of Arista Networks, Inc. All other company names are trademarks of their respective holders. Information in this document is subject to change without notice. Certain features may not yet be available. Arista Networks, Inc. assumes no responsibility for any errors that may appear in this document. 10/2018