References
Related Documents
The following documentation is available for Arista VeloCloud SD-WAN:
The following documentation is available for Arista VeloCloud SD-WAN:
This section explains how to deploy and operate an on-premises VeloCloud SD-WAN solution, including the Orchestrator.
This section explains how to deploy and operate an on-premises VeloCloud SD-WAN solution, which includes the VeloCloud Orchestrator, the VeloCloud Controller, and a co-located Edge Hub Cluster. It includes a reference architecture and the requirements and caveats for an on-premises SD-WAN deployment. It also covers the optional use of an External Certificate Authority and FIPS mode.
The reference architecture shows the logical grouping of the different VeloCloud SD-WAN and network functions. It also shows how the different nodes connect and communicate with each other. We expect that most real-world deployments would adapt the reference architecture in some way to accommodate their existing customer network.
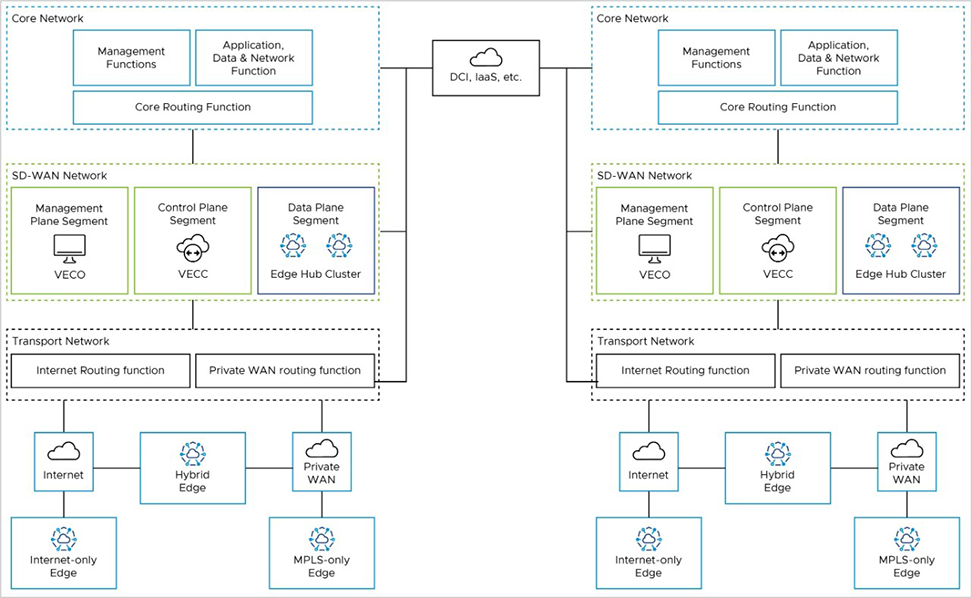
Core Network
The Core Network has applications and resources that users need to access to achieve their business goals. It may also have management functions, such as network monitoring and operations. If you use an External Certificate Authority (ECA), it may reside here. Data Center Interconnect (DCI, if you have it) also ends here from a routing perspective. You may separate these functions into different logical network segments.
SD-WAN Network
The SD-WAN Network is between the Transport Network and the Core Network. It has the Orchestrator (management plane), the Controller (control & routing plane), and the on-premises Hub Cluster (data plane), if you have one. These are all in the SD-WAN Network, but you may separate the Hub Cluster from the Orchestrator and Controller logically. This way, you can keep the SD-WAN management and control-plane traffic away from the branch data-plane traffic that uses the Hub Cluster to reach the core network resources.
Transport Network
The Transport Network has the WAN transport functions in the network, such as Public WAN (internet) and Private WAN (MPLS).
The Transport Network also has the Wide Area Network routing functions. This is where you would find Public WAN (internet) routers and Private WAN (MPLS CE) routers in an on-prem customer network. You may do NAT between public and private IP addresses here, or on an Edge firewall, depending on your network setup. You can also use wireless WAN (5G, for example) in the Public WAN case.
Firewalls
While not explicitly shown in the reference architecture, firewalls may be present. They may be deployed between the different functional blocks to provide security and traffic inspection or may be used to create different segments or zones within a functional block.
This section illustrates the packet flow path in the reference architecture for various operations.
Edge Activation
An internet-only branch location activates via a public WAN through the Internet Routing Function in the Transport Network to the public IP address of the Orchestrator (solid red line).
An MPLS-only branch location activates to the Orchestrator through the Private WAN Routing Function in the Transport Network, then through the Core Routing function in the Core Network, to the Orchestrator’s private IP address (dashed red line).
A hybrid Edge location may use either.
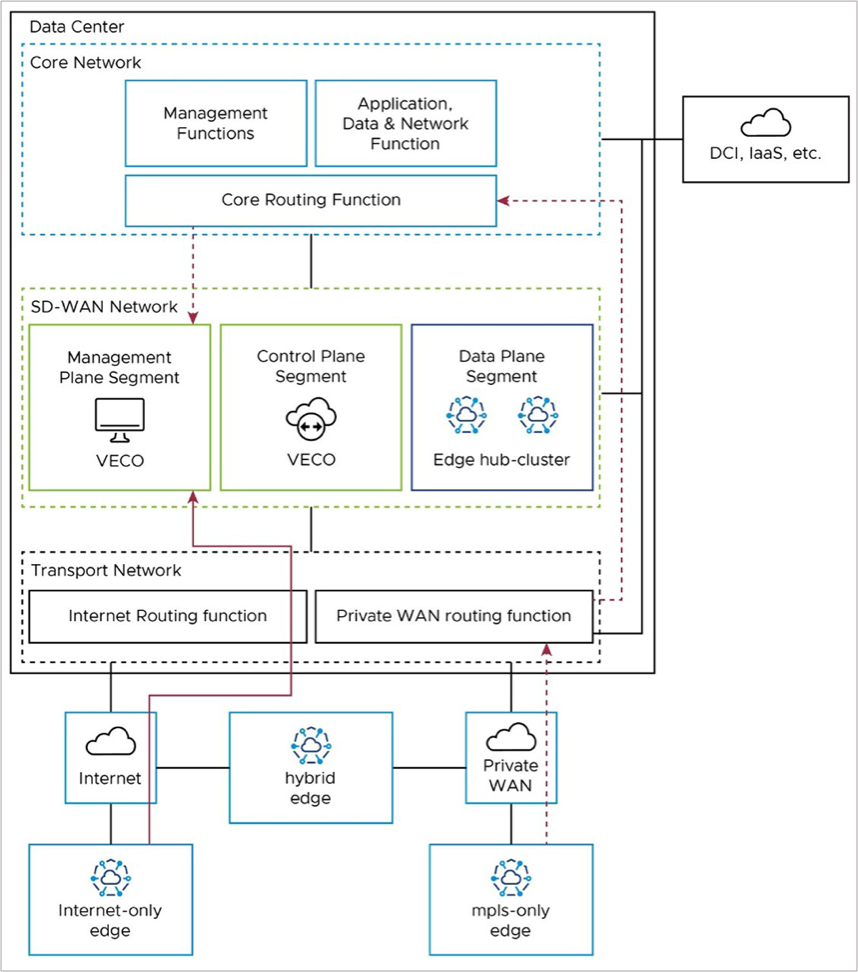
Management Plane: Edge to Orchestrator (VECO)
After activation, Edges use their Loopback IP addresses to connect to the Orchestrator. The Edge puts this connection inside the tunnel to the Controller, using any transport tunnel available. This connection then goes out of the Controller through its eth1 connection to the core network and reaches the Orchestrator. The Controller keeps the Loopback IP address as the source (no SNAT as with 1-arm Controller). The Orchestrator then replies to the Edge with its loopback address, which is dynamically routable via the Controller eth1 interface for symmetric routing.
Activated Edges may also communicate directly with the Orchestrator via the underlay, in which case they would use the same packet flow paths as in the Activation section.
If Edges use the SD-WAN overlay via the Controller (also called the VECC), the path depends on the Edge type. Internet-only Edges use the SD-WAN overlay via Public WAN to the public IP of the Controller (solid red line in the diagram), where they leave the tunnel, and go from the Controller's public IP address to the public IP address of the Orchestrator (solid blue line in the diagram).

Control Plane: Edge to Controller (VECC)
All Edges connect to the Controller (also referred to as the VeloCloud Edge Cloud Controller, or VECC) with SD-WAN overlay tunnels. Usually, Edges have a Primary and Secondary Controller for backup. But for simplicity, we only show one Controller in the diagram.
Internet-only Edges connect to the Controller's public IP address with an SD-WAN overlay tunnel over the public internet. They use the Internet routing function in the Transport Network (solid red line in the diagram). MPLS-only Edges also connect to the Controller with an SD-WAN overlay tunnel, but they use the Controller's private IP address. They use the Private WAN routing function in the Transport Network and the Core Routing function in the Core Network (solid red line in the diagram).
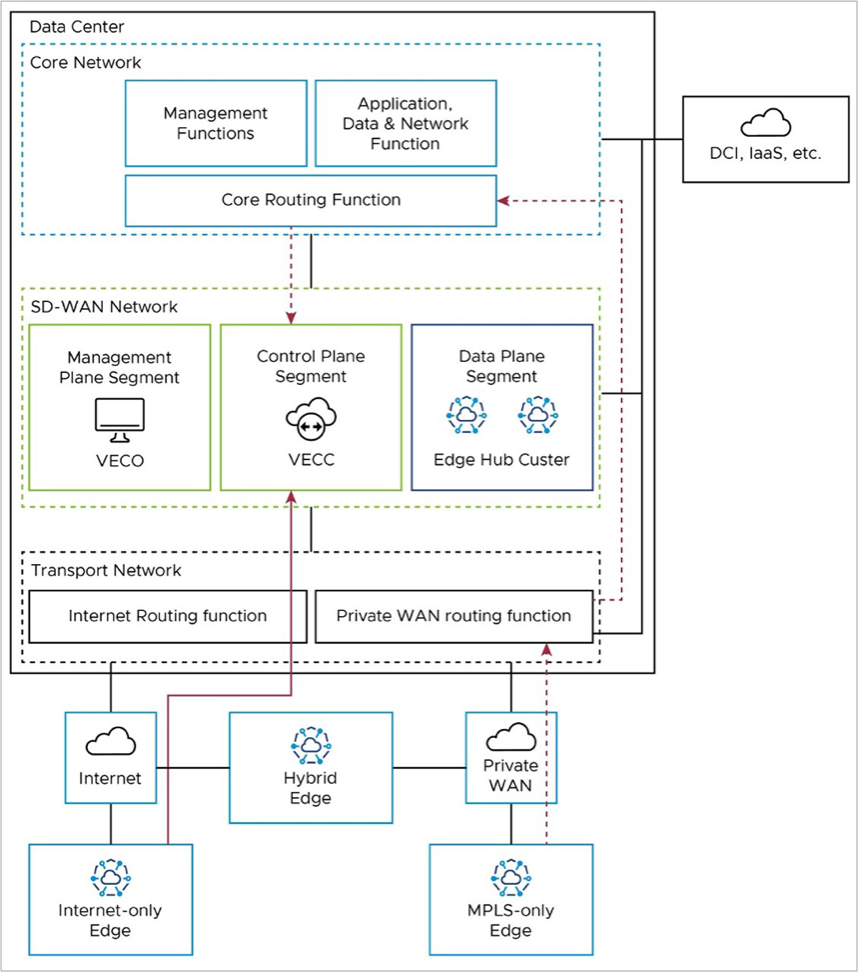
Hub Cluster to Controller (VECC)/Orchestrator (VECO): Special Case
The on-premises Hub Cluster provides a data path from Edge locations to the Core network, where the applications and resources are hosted. Usually, the Hub connects to a data center and accesses the Orchestrator and Controller remotely. So, the Hub Cluster needs to use public IP addresses to communicate with the Orchestrator/Controller; it cannot use the LAN-side / private IP network. To make the Hub Cluster look like it is at a remote location and access the Orchestrator/Controller over the public internet, you may need to put the Hub Cluster in a separate network segment (for example, VRF). You may also need hairpin NAT functionality on a network device on the WAN side of the Hub Cluster, Controller, and Orchestrator.
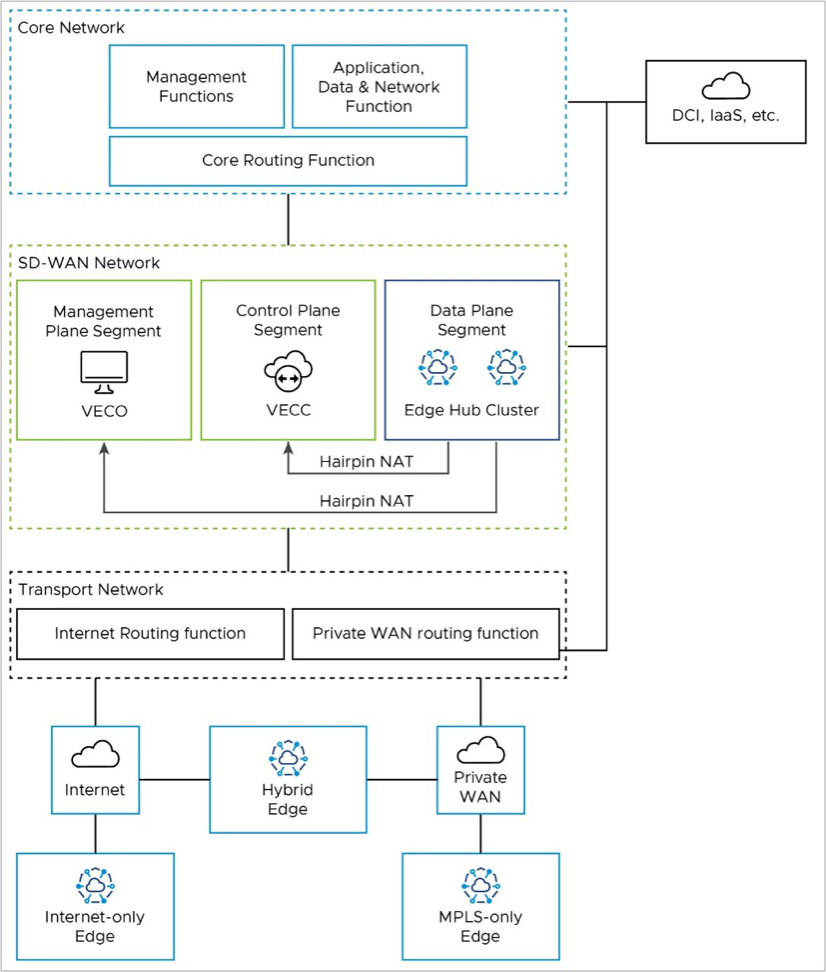
Edge to Core Network Functions – Data Path
Branch Edges access applications and resources in the datacenter via the on-premises Edge Hub Cluster. Internet-only Edges establish an SD-WAN overlay tunnel to the public WAN IP address of the Hub Cluster via the Internet routing function in the Transport Network (solid red line). Similarly, MPLS-only Edges establish an SD-WAN overlay tunnel to the private WAN IP address of the Hub Cluster via the private routing function in the Transport Network (dashed red line).
Once the data path reaches the Hub Cluster, it is removed from the SD-WAN tunnel and natively routed to applications in the core network via the Core Routing Function (solid blue lines).
This path is shared by all Edge types. Hybrid locations may use a combination of public and private SD-WAN overlays to the Edge Hub Cluster.
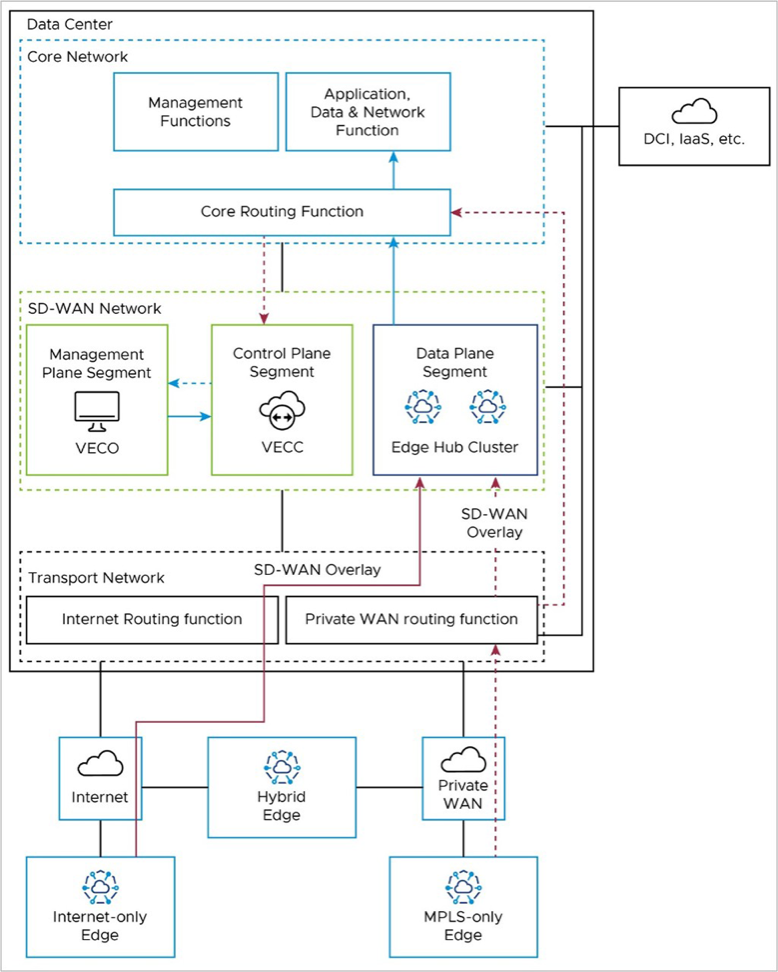
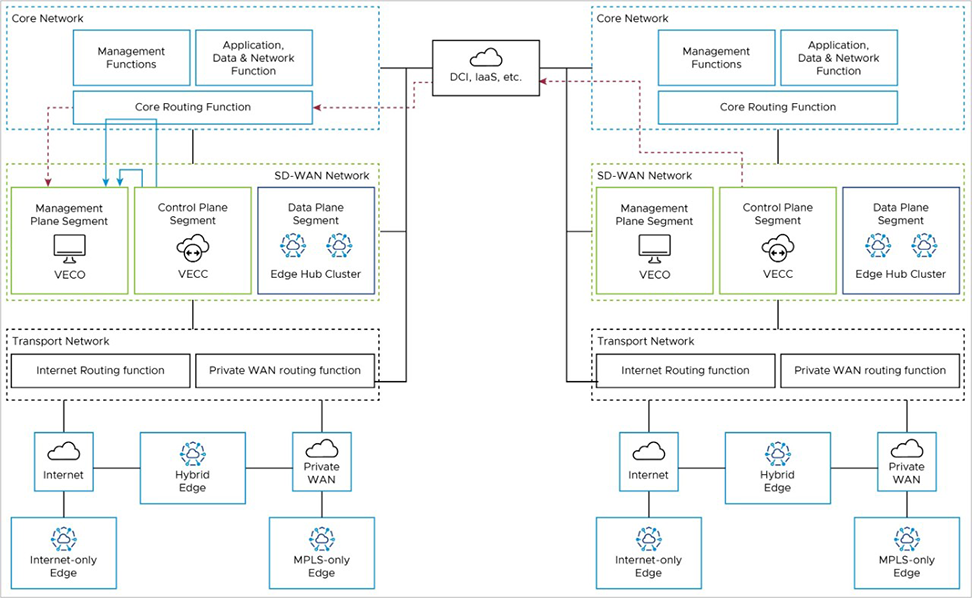
When two Edge Cloud Orchestrators (VECOs, or Orchestrators) are deployed as an Active-Standby Disaster Recovery (DR) pair in geographically diverse data center locations, there is both a real-time synchronization function (for configurations, alarms, metrics, etc.) between the active and standby, as well as a keep-alive function (to detect the failure of the active Orchestrator). This data path uses the private IP address of the Orchestrator, and uses a Data Center Interconnect to reach the remote DC via Core Routing function (red line).
Additional details on Orchestrator Disaster Recovery may be found in the Configure Orchestrator Disaster Recovery section.

The Orchestrator (management plane node) must communicate with the Controller (control plane node). In an on-premises deployment, this is done using the private IP addresses associated with the core network facing interfaces.
Depending upon the DR configuration and the location of the active Orchestrator (in the local or remote DC), this connectivity may take different paths.
For a co-located Orchestrator and Controller, the nodes may communicate directly within the SD-WAN Network block, or pass to the Core Routing Function (solid blue lines).
For a remote Orchestrator and Controller, the Controller must use the Core Routing function and DCI to reach the DR-active Orchestrator (dashed red lines).
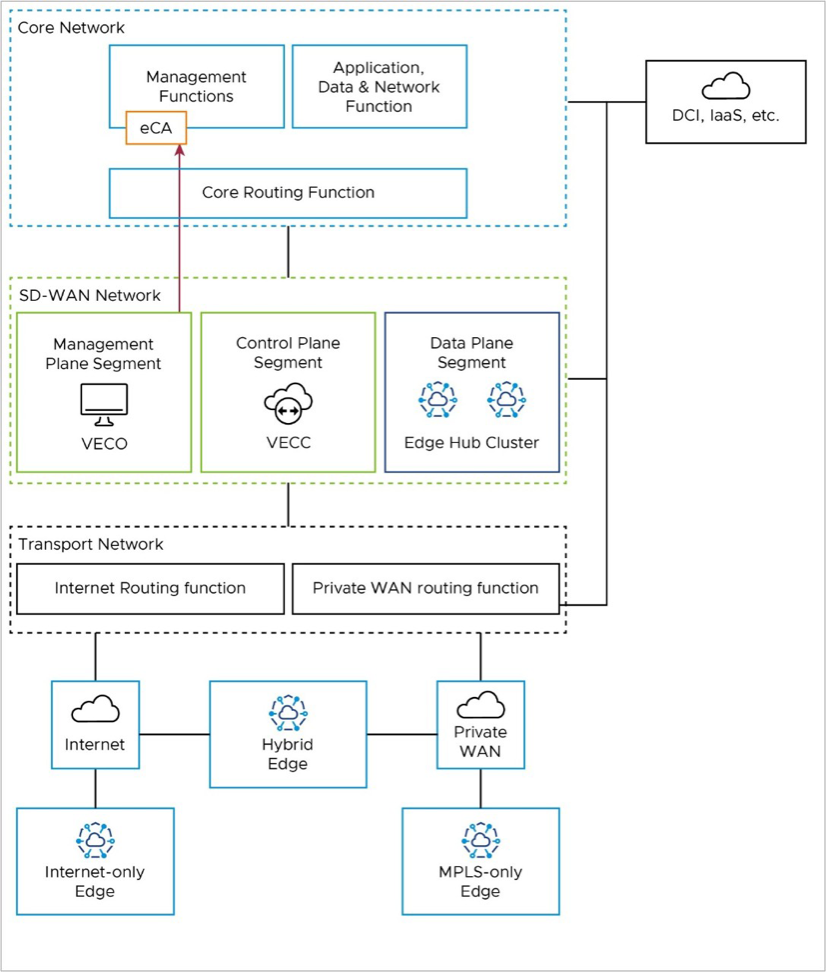
If an External CA (eCA) is used in the deployment, it would most likely reside in the Management Functions of the Core Network. The Orchestrator would use the private IP address of the core network facing interface to reach the eCA via the Core Routing Function.
If the Orchestrator is deployed as an active-standby DR pair, the Orchestrator fail-over may require the Orchestrator to reach the eCA via DCI.
Additional details on External CA may be found here:

While most real networks would have a more complex design, the expectation is that this design can be extrapolated to a real network with which it is being integrated.
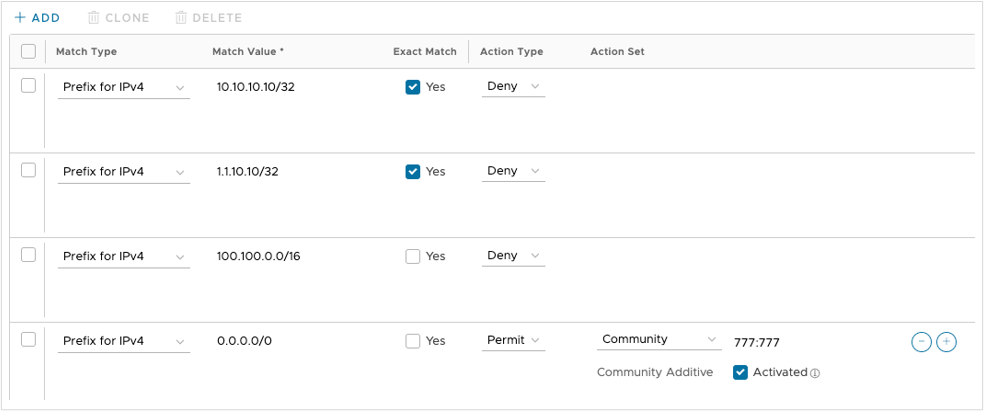
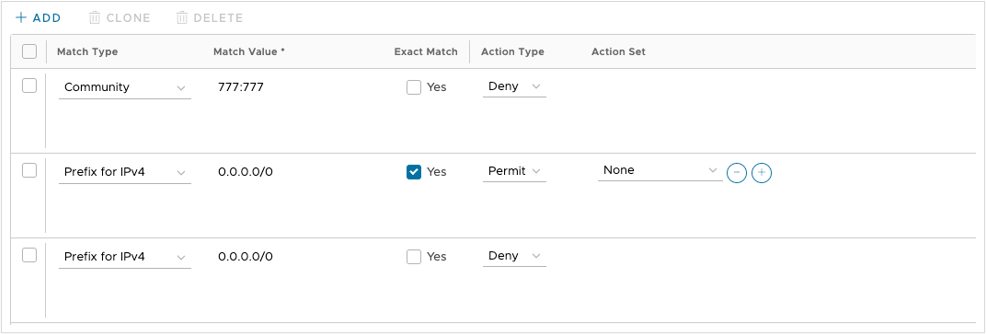
Network Address Translation (NAT) is used at the Hub Edge. It can be avoided if all components (Orchestrator, Controller, and Edges) are provided public IP addresses directly on their interface, but this is uncommon due to security requirements and limited IPv4 addresses in some networks.
The same requirement is necessary for inbound traffic on eth4, as public (internet only) Edges attempting to communicate to Orchestrator using VCOs public IP address (1.1.10.10) will egress the vcc on eth1 and route through the data center core to the internet edge, inbound on eth4.
nat {
destination {
rule 10 {
destination {
address 1.1.10.10
}
inbound-interface eth0
translation {
address 10.10.10.10
}
}
rule 15 {
destination {
address 1.1.10.10
}
inbound-interface eth4
translation {
address 10.10.10.10
}
}
rule 20 {
destination {
address 1.1.10.20
}
inbound-interface eth0
translation {
address 10.10.10.20
}
}
}
source {
rule 20 {
outbound-interface eth1
source {
address 10.10.10.20
}
translation {
address 1.1.10.20
}
}
rule 999 {
outbound-interface eth0
translation {
address masquerade
}
}
}
}Orchestrator Routing
Controller Routing
Controller SD-WAN Control Plane Routing
Orchestrator Connections
Controller Connections
Edge Connections
The Orchestrator, Controller (here referred to as the Gateway), and Edge all boot from a mounted ISO file for their initial bootstrap configuration. This ISO file uses the Linux cloud-init method. Cloud-init consists of YAML files. YAML files are created, and genisoimage is used to create an ISO for each VM.
On the Linux machine, create three YAML files each for Orchestrator and Gateway: meta-data, network-config, and user-data. Create two files for Edge: user-data and meta-data. Arrange in directory structure to match the following:
isos/
|
|--VCG
| |--meta-data
| |--network-config
| |--user-data
|
|--VCE
| |--meta-data
| |--user-data
|
|--VCO
| |--meta-data
| |--network-config
| |--user-datahostname: vco-1
password: Velocloud123
chpasswd:
expire: false
ssh_pwauth: true
velocloud: null
fips_mode: compliant
vco: null
super_users:
list: This email address is being protected from spambots. You need JavaScript enabled to view it.:Velocloud123
'
remove_default_users: falseversion: 2
ethernets:
eth0:
addresses:
- 10.10.10.10/28
routes:
- to: 0.0.0.0/0
via: 10.10.10.1
metric: 0
nameservers:
addresses:
- 10.10.10.1
eth1:
addresses:
- 172.16.1.18/28
routes:
- to: 10.20.0.0/16
via: 172.16.1.17
metric: 0
- to: 172.16.0.0/12
via: 172.16.1.17
metric: 0
- to: 192.168.0.0/16
via: 172.16.1.17
metric: 0instance-id: vco-1
local-hostname: vco-1hostname: vcc-1
password: Velocloud123
chpasswd:
expire: false
ssh_pwauth: true
velocloud: null
fips_mode: compliantversion: 2
ethernets: null
eth0:
addresses:
- 1.1.1.10/28
routes:
- to: 0.0.0.0/0
via: 1.1.1.1
metric: 0
nameservers:
addresses:
- 1.1.1.1
eth1:
addresses:
- 172.16.1.10/28
routes:
- to: 0.0.0.0/0
via: 172.16.1.1
metric: 5
- to: 172.16.1.16/28
via: 172.16.1.1
metric: 0instance-id: vcc-1
local-hostname: vcc-1hostname: vce
password: Velocloud123
chpasswd:
expire: false
ssh_pwauth: trueinstance-id: vcecd iso
cd vco
genisoimage -output cdrom.iso -volid cidata -joliet -rock user-data meta-data network-config
cd ..
cd vcc
genisoimage -output cdrom.iso -volid cidata -joliet -rock user-data meta-data network-config
cd ..
cd vce
genisoimage -output cdrom.iso -volid cidata -joliet -rock user-data meta-data
cd ..cdrom.iso added to each directory:
isos/
|
|--VCG
| |--cdrom.iso
| |--meta-data
| |--network-config
| |--user-data
|
|--VCE
| |--cdrom.iso
| |--meta-data
| |--user-data
|
|--VCO
| |--cdrom.iso
| |--meta-data
| |--network-config
| |--user-data
network.public.address.gateway.activation.validate.source.vcg-1 login: vcadmin
Password:
Welcome to Velocloud OS (GNU/Linux 4.15.0-1113-fips x86_64)pool 10.10.10.1 iburst
sudo service ntp restart
sudo ntpq -c peerssudo ntpq-p"wan": ["eth1"],
"geneve": ["eth1"],sudo rebootsudo sucd /opt/vc/binactivate.py -I -s 172.16.1.18 <activation
key>Activation successful, VCO overridden back to 172.16.1.18edge-imageupdate-VC_VMDK-x86_64-5.2.0.2-83770177-R5202-20230725-GA-6969b39047
This section provides an overview of the implementation of Federal Information Processing Standard (FIPS) on the Orchestrator and Gateways, encompassing the three operational modes and the procedures necessary to activate FIPS mode.
The Federal Information Processing Standards of the United States are a set of publicly announced standards that the National Institute of Standards and Technology (NIST) has developed for use in computer systems of non-military United States government agencies and contractors.
FIPS 140-2 certification for cryptographic modules enables organizations to meet compliance requirements within the public sector, healthcare, and finance industries. It defines the critical security parameters that must be used for encryption in the products sold into the U.S. public sector. FIPS 140-2 is, therefore, required under multiple compliance programs, such as Federal Risk and Authorization Management Program ( FedRAMP), Federal Information Security Management Act of 2002 (FISMA) and the Health Information Technology for Economic and Clinical Health Act (HITECH).
FIPS certification ensures that software has been thoroughly reviewed and tested before being deployed and utilized within an agency or organization requiring data encryption. Industries storing and processing sensitive data that spans outside the public sector space, leading to FIPS-certified software being widely adopted within the payment card industry, healthcare, and other regulated industries.
Ciphers:
AES128-CTR, AES192-CTR, AES256-CTR
MACS:
HMAC-SHA2-256, HMAC-SHA2-512
Key Exchange:
EDCH-SHA2-NISTP521, ECDH-SHA2-NISTP384, ECDH-SHA2-NISTP256, Diffie-Hellman-Group-Exchange-SHA256
FIPS-mode operation also enables an application security system on the Orchestrator and Gateway. This includes an allowlist of core applications used by the SD-WAN appliances, and a denylist of processes that should never be allowed.
The application security system also prevents unauthorized access from within existing processes, such as file access, external executable processes, and so forth. Unauthorized access attempts are recorded in an audit log, which can be viewed using the “aa-logprof” CLI command.
Non-FIPS Mode
This is the default mode of operation. SD-WAN appliances are capable of using non-FIPS-approved ciphers such as Triple DES (3DES), and all software packages can be updated.
FIPS Compliant Mode
SD-WAN appliances are capable of only using FIPS-approved ciphers, and the software package can be updated to include a FIPS module that is patched for security vulnerability but not tested by NIST.
FIPS Strict Mode
SD-WAN appliances are capable of only using FIPS-approved ciphers, and only non-cryptographic software packages may be updated. For systems running in “Strict FIPS mode”, FIPS system components will not receive regular security updates. These modules will be updated when new validated FIPS modules are available.
The Orchestrator and Gateways are appliances that run as virtual machines. FIPS mode may be enabled for them during instantiation using a cloud-init file, or after instantiation using a CLI command.
However, there is no impact to an Orchestrator already in FIPS mode if a user transitions it from “Strict” to “Compliant”.
Enabling FIPS via Cloud-Init File
For both the Orchestrator and Gateways, the mode of operation (FIPS mode versus non-FIPS mode) can be specified in cloud-init during the VM spin up process. If no flags are set, the system will default to non-FIPS mode.
fips_mode: strict should be added to the user-data portion of the cloud-init file as shown in the example below:
velocloud:
fips_mode: strictIf no flags are set, the system will instantiate in the “default” mode of “FIPS disabled”.
Enabling FIPS via the Command Line
sudo /opt/vc/bin/vc_fips_enable --mode=[strict|compliant] [--no-reboot] [--noninteractive]$ cat /opt/vc/etc/fips/fips.json
{"fips_mode": "compliant", "prev_fips_mode": "none"}
$ cat /proc/sys/crypto/fips_enabled
1
$ dmesg |grep -i "fips mode"
[ 0.000000] fips mode: enabledIf the Orchestrator fails to upgrade due to a FIPS error, first check if the fips.cnf file exists at /etc/mysql/conf.d.
[mysqld]
ssl_fips_mode=1
This guide covers the use of certificates and the expected functions of an external certificate authority (CA). We will cover what an external CA is and what it does, the different types of certificates and the requirements for each, and some tips for troubleshooting if you run into any issues. All these elements are discussed in the context of an Orchestrator deployed on-premises.
This chain of certificates is distributed by the Orchestrator to Edges and Gateways to allow for mutual, certificate based authentication during the establishment of SD-WAN overlay tunnels.
The chain must be continuous from a leaf certificate to a self-signed root certificate. The chain need not be rooted by a well-known public issuer, the root can be a private self-signed certificate.
CRLs generated by the customer’s external CA are distributed by the Orchestrator to Edges and Gateways. Edges and Gateways do not communicate directly with the external CA. Also, the Orchestrator may be configured to automatically fetch CRLs from a CRL distribution point, or CRLs may be manually updated to the Orchestrator.

Edges and Gateways generate RSA key pairs and CSRs when certificate enrollment or renewal is requested. The Orchestrator receives the CSR via the device heartbeat. From the Orchestrator the CSR can be delivered by several mechanisms to the customer CA, receiving a signed certificate in return.
There are two types of certificates, one for Edges, and the second for Gateways. Only the Common Name (CN) is reserved for SD-WAN use.
Only one CN can be defined. Other fields in the Distinguished Name (DN) are free for use by the external CA. For help in obtaining the Edge and Gateway Logical-IDs, see the section below “Locating Logical-IDs".

Example: Certificate and CSR Subject Names (DNs)
Integration with an external CA requires flexibility in both the generation of CSR subject names and in the handling of certificate subject names by both the Management Plane and the Data Plane.
Locating Logical IDs for use in Certificate Creation
In the Orchestrator, the Edge Logical-ID may be found in the “Logical ID” column by going to . If it is not displayed, select “Columns” at the bottom of the screen and select it.
The Gateway Logical ID may be found on the Orchestrator UI by logging in as an Operator level user and navigating to . Select the desired Gateway, then select the drop-down next to the Gateway name to obtain details about the Gateway, including its logical ID.
1. Expose a rooted chain of trust in the form of one or more PEM-encoded certificates.
The PEM-encoded chain can be manually configured on the Orchestrator at the time of external CA definition on the Orchestrator, in the Orchestrator UI. The chain can be pulled from the External CA, or from customer middleware by API at the time of External CA definition on the Orchestrator.
2. Provision of signed certificate revocation lists.
CRLs may be manually pushed to the Orchestrator via API, manually uploaded to the Orchestrator from the Orchestrator UI, or pulled by the Orchestrator from a CRL distribution point on a configured schedule. The CRL distribution point is defined by an HTTP URL visible to the Orchestrator, and is configured when the CA is defined.
3. Certificate Enrollment


Certificate enrollment can also be automated by a custom integration developed in conjunction with Arista Professional Services.
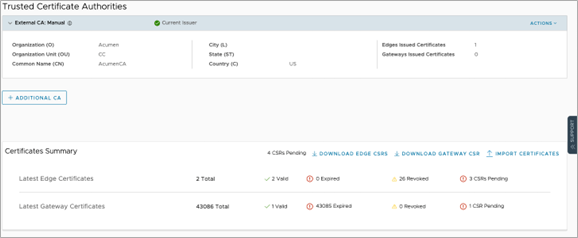
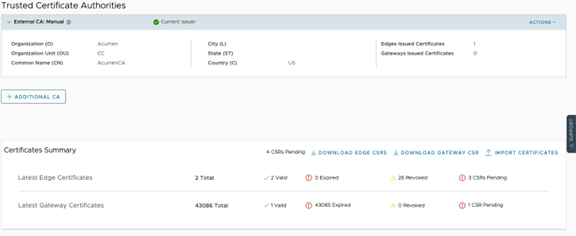
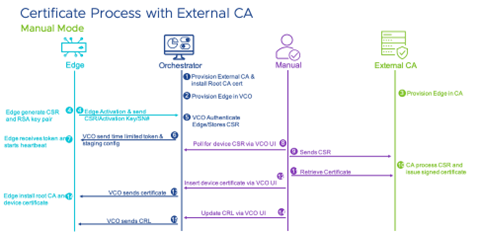
Manual Mode
The Orchestrator presents a UI allowing the user to poll/request CSR, install root CA's certificate and device certificate, and CRLs. This process is very similar to the Middleware mode using Southbound API, but instead of APIs, users interface with Orchestrator through UI.
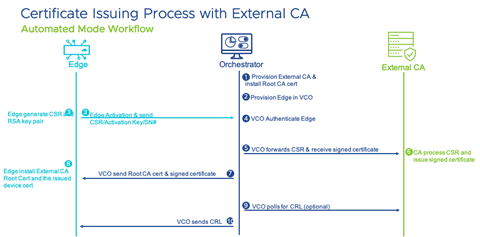
Automated Mode
The Orchestrator integrates directly with an external CA (EJBCA, MS CA, etc) through REST APIs for certificate request, renewal, and revocation.
Middleware (Asynchronous) Mode
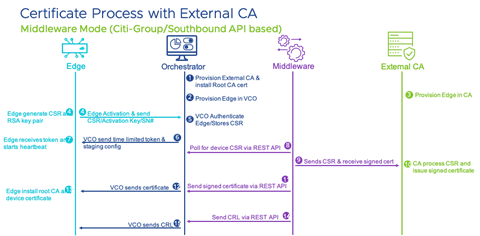
This section offers guidance on how to resolve common issues experienced when deploying and operating an external CA.
Edges Deployed in High Availability (HA)
When two Edges are deployed in HA, there will be two certificates shown under a single Edge in . In manual mode, a separate certificate must be generated by the external CA using the CSRs for the Active and Standby Edges.
Edges starting from the 5.1.0 version can enable HA as they are compatible with External CA. Edges running version 5.0.x or earlier software are not supported with external CA.
Connection Errors Due to Certificate Mismatches
If an Edge or Gateway fails to connect, it may be the result of a certificate mismatch. The first step is to check if the Edge or Gateway has Authentication Mode set to Certificate Acquire. A certificate mismatch can be indicated by logging into the CLI of the Edge or Gateway and viewing the output of the mgd.log file using the sudo tail –f /var/log/mgd.log command.
The certificates that have been pushed to the Edge and Gateway can also be decoded using the openssl utility in Linux and compared to the certificate in the Orchestrator. These certificates, as well as PKI keys derived from them, are stored on the Edge and Gateway in /etc/vc_private and /etc/vc_public.
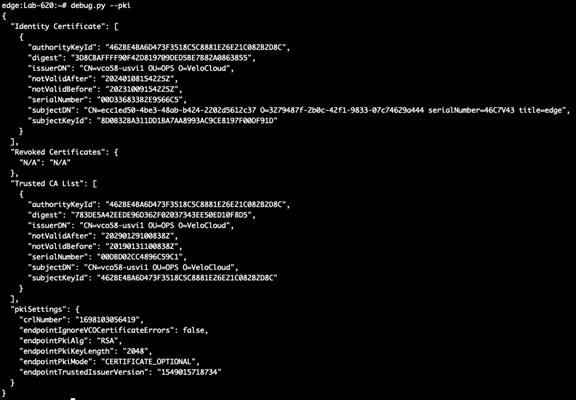
Utility: debug.py--pki
The debug.py –pki utility may be used from the Edge or Gateway command line interface to view details about PKI settings, the trusted CA list, and the certificate:
Utility: debug.py--ike_sa
The debug.py --ike_sa utility can be used to show the details of current security associations. In the example below, the three existing security associations correspond to the Orchestrator and Primary and Secondary Gateways, respectively:

Utility: debug.py--ike_spd
Details of security protocols and encryption methods used per peer can be found using the debug.py --ike_spd utility:

Decoding Certificates using OpenSSL
The details and contents of certificates may be viewed by using the Linux openssl tool. It will show you the details of the certificate like Version, Serial Number, Signature Algorithm, Issuer, Validity, Subject, Public Key Algorithm and many more.
The VeloCloud Orchestrator Deployment and Monitoring Guide provides guidance on how to install, run, and monitor the Orchestrator.
The VeloCloud SD-WAN Orchestrator Deployment and Monitoring Guide provides guidance on how to install, run, and monitor the Edge Cloud Orchestrator.
This section discusses the Orchestrator installation.
This section discusses the prerequisites that must be met before installing the Orchestrator .
Arista recommends installation of the Orchestrator and Gateway applications as a virtual machine, for example, as a guest instance, on an existing hypervisor.
The upstream firewall needs to be configured to allow inbound HTTP (TCP/80) as well as HTTPS (TCP/443). If a stateful firewall is in place, established outbound connections should also be allowed to facilitate upgrades and security updates.
The Orchestrator relies on several external services. Before proceeding with an installation, ensure you have available licenses for each of the services.
Google Maps displays Edges and data centers on a map, and does not require a Google account with Google to utilize the functionality. However, Internet access must be available to the Orchestrator instance in order for the service availability.
The service is limited to 25,000 map loads each day for more than 90 consecutive days. VeloCloud does not anticipate exceeding these limits for nominal use of the Orchestrator. For additional information, see Configure System Properties for Google Maps.
VeloCloud uses Twilio for SMS-based alerting to enterprise customers and notifies them of Edge or link outage events. An account needs to be created and funded at http://www.twilio.com.
The account can be provisioned in the Orchestrator through the Operator Portals System Properties page. The account provisions through a system property, as described later in the guide. See Configure System Properties for Twilio for additional information.
MaxMind provides geolocation services and automatically detects Edge and Gateway locations and ISP names based on IP address. If this service deactivates, then you must update the geolocation information updated manually. The account can be provisioned in the Orchestrator through the Operator Portal's System Properties page. See Configure System Properties for MaxMind for additional information.
This section discusses Orchestrator installation.
This section discusses how to use the cloud-init package to handle the early initialization of instances.
Cloud-init consists of a Linux package responsible for handling the early initialization of instances. If available in the distributions, it allows for configuration of many common parameters of the instance directly after installation. This creates a fully functional instance with a configuration based on a series of inputs.
Cloud-init behavior can be configured with user data. Provide the user data at the instance launch time and attach a secondary disk in ISO format that cloud-init searches for at first boot time. This disk contains all early configuration data to apply at that time.
The Orchestrator supports cloud-init and all essential configurations packaged in an ISO image.
The final installation configuration options are set with a pair of cloud-init configuration files. The first installation configuration file contains the metadata. Create this file with a text editor and label it metadata. This file provides information that identifies the instance of Orchestrator to be installed. The instance-id can be any identifying name, and the local-hostname should be a host name that follows your site standards, for example:
instance-id: vco01
local-hostname: vco-01Additionally, you can specify network interface information if the network does not have a DHCP configuration, for example:
instance-id: vco01
local-hostname: vco-01
network-interfaces: |
auto eth0
iface eth0 inet static
address 10.0.1.2
network 10.0.1.0
netmask 255.255.255.0
broadcast 10.0.1.255
gateway 10.0.1.1The second installation configuration option file contains the user data. This file provides information about users on the system. Create it with a text editor and name it user-data. This file enables access to the installation of Orchestrator. The following provides an example of the user-data file:
#cloud-config
password: Velocloud123
chpasswd: {expire: False}
ssh_pwauth: True
ssh_authorized_keys:
- ssh-rsa AAA...SDvz This email address is being protected from spambots. You need JavaScript enabled to view it.
- ssh-rsa AAB...QTuo This email address is being protected from spambots. You need JavaScript enabled to view it.
vco:
super_users:
list: |
This email address is being protected from spambots. You need JavaScript enabled to view it.:password1
remove_default_users: True
system_properties:
list: |
mail.smtp.port:34
mail.smtp.host:smtp.yourdomain.com
service.maxmind.enable:True
service.maxmind.license:todo_license
service.maxmind.userid:todo_user
service.twilio.phoneNumber:222123123
network.public.address:222123123
write_files:
- path: /etc/nginx/velocloud/ssl/server.crt
permissions: '0644'
content: "-----BEGIN CERTIFICATE-----\nMI….ow==\n-----END CERTIFICATE-----\n"
- path: /etc/nginx/velocloud/ssl/server.key
permissions: '0600'
content: "-----BEGIN RSA PRIVATE KEY-----\nMII...D/JQ==\n-----END RSA PRIVATE KEY-----\n"
- path: /etc/nginx/velocloud/ssl/velocloudCA.crtchpasswd lines.
chpasswd line turns off password expiration to prevent the first login from immediately prompting for a change of password. This is optional.The ssh_pwauth line enables SSH login. The ssh_authorized_keys line begins a block of one or more authorized keys. Each public SSH key listed on the ssh-rsa lines will be added to the vcadmin ~/.ssh/authorized_keys file.
In this example, two keys are listed. For this example, the key has been truncated. In a real file, the entire public key must be listed. Note that the ssh-rsa lines must be preceded by two spaces, followed by a hyphen, followed by another space.
The vco section specifies configured Orchestrator services.
super_users contains list of Super Operator accounts and corresponding passwords.
The system_properties section allows to customize Orchestrator System Properties. See System Properties for details regarding system properties configuration.
server.crt and server.key files in the /etc/nginx/velocloud/ssl/ folder with user-supplied files.
server.key file must be unencrypted. Otherwise, the service fails to start without the key password.Once you have completed your files, package them into an ISO image. Use the ISO image as a virtual configuration CD with the virtual machine. This ISO image, called vco01-cidata.iso, is created with the following command on a Linux system:
genisoimage -output vco01-cidata.iso -volid cidata -joliet -rock user-data meta-dataTransfer the newly created ISO image to the datastore on the host running VeloCloud.
VMware vSphere provides a means of deploying and managing virtual machine resources. This section explains how to run the Orchestrator using the VMware vSphere Client.
This section explains how to run the Orchestrator using the libvirt. This deployment was tested on an Ubuntu 18.04 LTS instance.
qcow images.
ROOTFSSTORESTORE2STORE3The images thin provision on deployment.
Start by copying the images to the KVM server. In addition, you must copy the cloud-init ISO build as described in the previous section.
<domain type='kvm' id='49'>
<name>vco</name>
<uuid>b0ff25bc-72b8-6ccb-e777-fdc0f4733e05</uuid>
<memory unit='KiB'>12388608</memory>
<currentMemory unit='KiB'>12388608</currentMemory>
<vcpu>2</vcpu>
<resource>
<partition>/machine</partition>
</resource>
<os>
<type>hvm</type>
</os>
<features>
<acpi/>
<apic/>
<pae/>
</features>
<cpu mode='custom' match='exact'>
<model fallback='allow'>SandyBridge</model>
<vendor>Intel</vendor>
<feature policy='require' name='vme'/>
<feature policy='require' name='dtes64'/>
<feature policy='require' name='invpcid'/>
<feature policy='require' name='vmx'/>
<feature policy='require' name='erms'/>
<feature policy='require' name='xtpr'/>
<feature policy='require' name='smep'/>
<feature policy='require' name='pbe'/>
<feature policy='require' name='est'/>
<feature policy='require' name='monitor'/>
<feature policy='require' name='smx'/>
<feature policy='require' name='abm'/>
<feature policy='require' name='tm'/>
<feature policy='require' name='acpi'/>
<feature policy='require' name='fma'/>
<feature policy='require' name='osxsave'/>
<feature policy='require' name='ht'/>
<feature policy='require' name='dca'/>
<feature policy='require' name='pdcm'/>
<feature policy='require' name='pdpe1gb'/>
<feature policy='require' name='fsgsbase'/>
<feature policy='require' name='f16c'/>
<feature policy='require' name='ds'/>
<feature policy='require' name='tm2'/>
<feature policy='require' name='avx2'/>
<feature policy='require' name='ss'/>
<feature policy='require' name='bmi1'/>
<feature policy='require' name='bmi2'/>
<feature policy='require' name='pcid'/>
<feature policy='require' name='ds_cpl'/>
<feature policy='require' name='movbe'/>
<feature policy='require' name='rdrand'/>
</cpu>
<clock offset='utc'/>
<on_poweroff>destroy</on_poweroff>
<on_reboot>restart</on_reboot>
<on_crash>restart</on_crash>
<devices>
<emulator>/usr/bin/kvm-spice</emulator>
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='/images/vco/rootfs.qcow2'/>
<target dev='hda' bus='ide'/>
<alias name='ide0-0-0'/>
<address type='drive' controller='0' bus='0' target='0' unit='0'/>
</disk>
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='/ images/vco/store.qcow2'/>
<target dev='hdb' bus='ide'/>
<alias name='ide0-0-1'/>
<address type='drive' controller='0' bus='0' target='0' unit='1'/>
</disk>
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='/ images/vco/store2.qcow2'/>
<target dev='hdc' bus='ide'/>
<alias name='ide0-0-2'/>
<address type='drive' controller='0' bus='1' target='0' unit='0'/>
</disk>
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2' />
<source file='/images/vco/store3.qcow2' />
<target dev='hdd' bus='ide' />
<alias name='ide0-0-3' />
<address type='drive' controller='0' bus='1' target='0' unit='1' />
</disk>
<disk type='file' device='cdrom'>
<driver name='qemu' type='raw'/>
<source file='/ images/vco/seed.iso'/>
<target dev='sdb' bus='sata'/>
<readonly/>
<alias name='sata1-0-0'/>
<address type='drive' controller='1' bus='0' target='0' unit='0'/>
</disk>
<controller type='usb' index='0'>
<alias name='usb0'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x2'/>
</controller>
<controller type='pci' index='0' model='pci-root'>
<alias name='pci.0'/>
</controller>
<controller type='ide' index='0'>
<alias name='ide0'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x1'/>
</controller>
<interface type='direct'>
<source dev='eth0' mode='vepa'/>
</interface>
<serial type='pty'>
<source path='/dev/pts/3'/>
<target port='0'/>
<alias name='serial0'/>
</serial>
<console type='pty' tty='/dev/pts/3'>
<source path='/dev/pts/3'/>
<target type='serial' port='0'/>
<alias name='serial0'/>
</console>
<memballoon model='virtio'>
<alias name='balloon0'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
</memballoon>
</devices>
<seclabel type='none' />
<!-- <seclabel type='dynamic' model='apparmor' relabel='yes'/> -->
</domain>To create the VM using the standard virsh commands:
virsh define vco.xml
virsh start vcoThis section discusses how to install Orchestrator on AWS.
See the first section of the Orchestrator Installation, Instance Requirements, and select an AWS instance type matching these requirements. Both CPU and Memory requirements must be satisfied. Example: use c4.2xlarge or larger; r4.2xlarge or larger
Request an AMI ID from VeloWare. It will be shared with the customer account. Have an Amazon AWS account ID ready when requesting AMI access.
Example: http://docs.aws.amazon.com/efs/latest/ug/gs-step-one-create-ec2-resources.html
This section discusses how to install an SSL certificate.
To install an SSL certificate:
This section discusses how to configure System Properties, which provide a mechanism to control the system-wide behavior of the VeloCloud SD-WAN.
System Properties can be set initially using the cloud-init config file. For additional information, see Cloud-init Preparation. The following properties need to be configured to ensure proper operation of the service.
Enter a fully qualified VeloCloud domain name in the network.public.address system property.
service.client.googleMapsApi.key system property to API key.service.client.googleMapsApi.enable to true.service.twilio.enable allows the service to be deactivated in the event that no Internet access is available to the VeloCloudservice.twilio.accountSidservice.twilio.authTokenservice.twilio.phoneNumber in (nnn)nnn-nnnn formatObtain the service at https://www.twilio.com.
service.maxmind.enable allows the service to be deactivated in the event that no Internet access is available to the VeloCloudservice.maxmind.userid holds the user identification supplied by MaxMind during the account creationservice.maxmind.license holds the license key supplied by MaxMindObtain the license at: https://www.maxmind.com/en/geoip-api-web-services.
mail.smtp.auth.pass- SMTP user password.mail.smtp.auth.user- SMTP user for authentication.mail.smtp.host- relay server for email originated from the VeloCloud.mail.smtp.port - SMTP port.mail.smtp.secureConnection- use SSL for SMTP traffic.This section discusses how to upgrade the Orchestrator.
To upgrade the Orchestrator:
All storage volumes are configured as LVM devices. They can be resized online by providing the underlying virtualization technology to support online disk expansion. Disks are expanded automatically via cloud-init when the VM boots.
To expand disks after boot:
VeloCloud provides System Properties to configure various features and options available in the Orchestrator portal.
In the Operator portal, navigate to the System Properties page, which lists the available pre-defined system properties. See List of System Properties, which lists some of the system properties that you can modify as an Operator.

To configure the system properties:
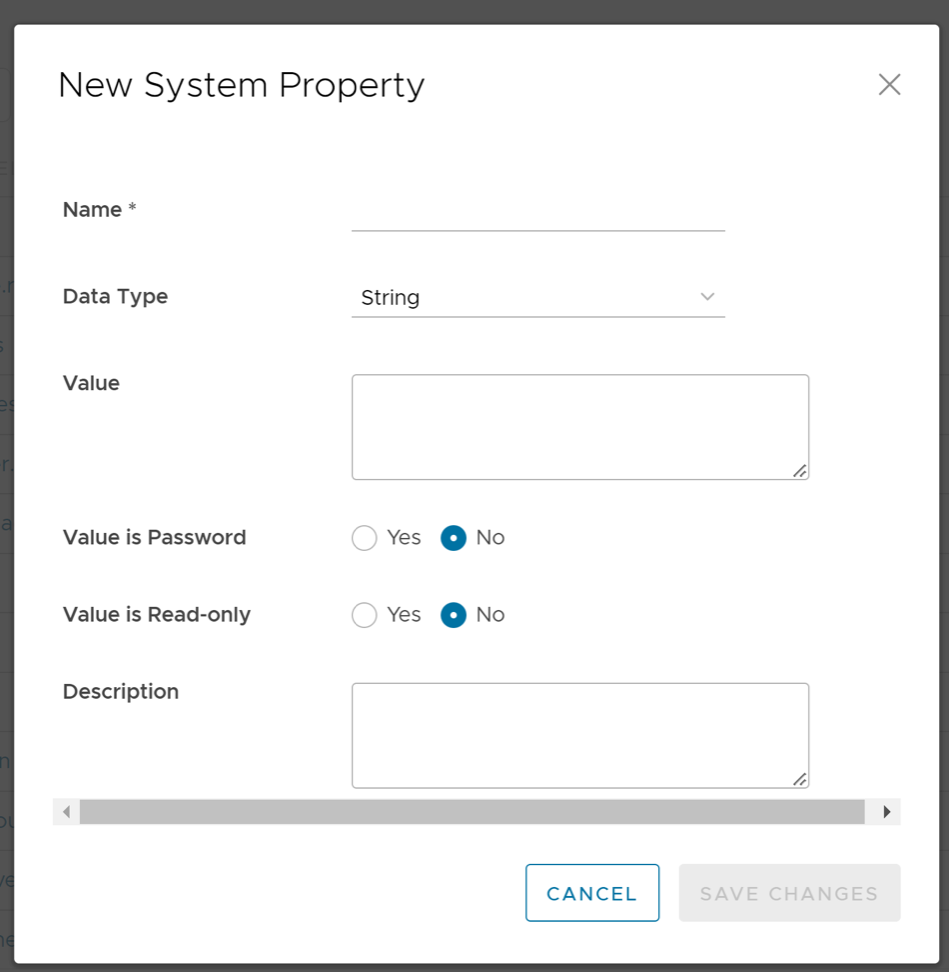
| Option | Description |
|---|---|
| Name | Enter the Name for the new system property. |
| Data Type | Choose the required Data Type from the drop-down menu. |
| Value | Enter the Value for the property according to the data type. |
| Value is Password | Select Yes or No as required. |
| Value is Read-only | Select Yes or No for as required. |
| Description | Enter the Description for the new system property |
As an Operator, you can add or modify the values of the system properties.
| System Property | Description |
|---|---|
vco.alert.mail.to |
When an alert is triggered, a notification is sent immediately to the list of Email addresses provided in the Value field of this system property. You can enter multiple Email IDs separated by commas.
If the property does not contain any value, then the notification is not sent. The notification is meant to alert Arista support / operations personnel of impending issues before notifying the customer. |
vco.alert.mail.cc |
When alert emails are sent to any customer, a copy is sent to the Email addresses provided in the Value field of this system property. You can enter multiple Email IDs separated by commas. |
mail.* |
There are multiple system properties available to control the Alert Emails. You can define the Email parameters like SMTP properties, username, password, and so on. |
| System Property | Description |
|---|---|
vco.alert.enable |
Globally activates or deactivates the generation of alerts for both Operators and Enterprise customers. |
vco.enterprise.alert.enable |
Globally activates or deactivates the generation of alerts for Enterprise customers. |
vco.operator.alert.enable |
Globally activates or deactivates the generation of alerts for Operators. |
| System Property | Description |
|---|---|
session.options.enableBastionOrchestrator |
Enables the Bastion Orchestrator feature.
For more information, see Bastion Orchestrator Configuration Guide. |
vco.bastion.private.enable |
Enables the Orchestrator to be the Private Orchestrator of the Bastion pair. |
vco.bastion.public.enable |
Enables the Orchestrator to be the Public Orchestrator of the Bastion pair. |
| System Property | Description |
|---|---|
edge.certificate.renewal.window |
This optional system property allows the Operator to define one or more maintenance windows during which the Edge certificate renewal is enabled. Certificates scheduled for renewal outside of the windows will be deferred until the current time falls within one of the enabled windows.
Enable System Property: To enable this system property, type "true" for "enabled" in the first part of the Value text area in the Modify System Property dialog box. An example of the first part of this system property when it is enabled is shown below. Operators can define multiple windows to restrict the days and hours of the day during which Edge renewals are enabled. Each window can be defined by a day, or a list of days (separated by a comma), and a start and end time. Start and end times can be specified relative to an Edge's local time zone, or relative to UTC. See image below for an example. 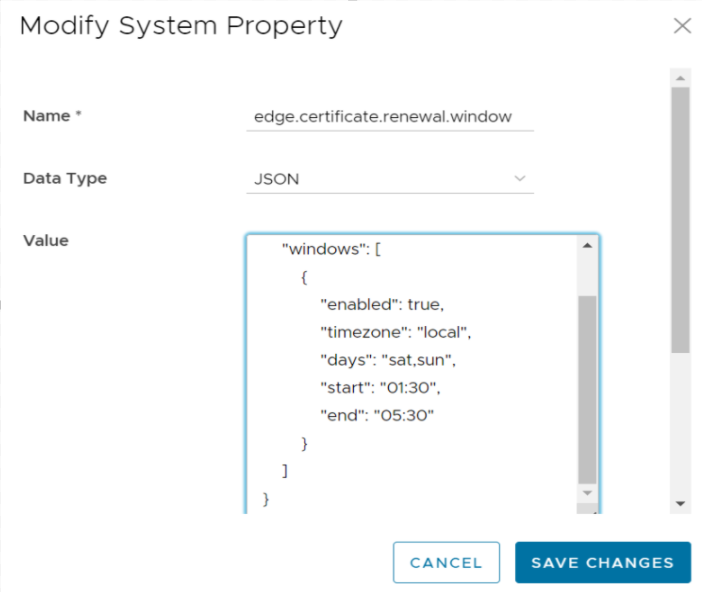 Note: If attributes are not present, the default is
false.When defining window attributes, adhere to the following:
If the above-mentioned values are missing, the attribute defaults in each window definition are as follow:
Deactivate System Property This system property is deactivated by default, which means the certificate will automatically renew after it expires. "Enabled" will be set to "false in the first part of the Value text area in the Modify System Property dialog box. An example of this property when it is deactivated is shown below. {
"enabled": false,
"windows": [
{
NOTE: This system property requires that PKI be enabled. |
gateway.certificate.renewal.window |
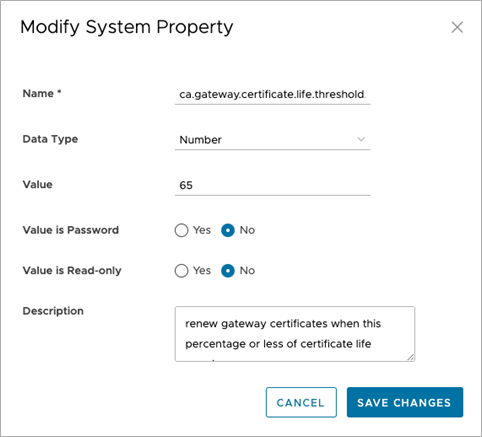
This optional system property allows the Operator to define one or more maintenance windows during which the Gateway certificate renewal is enabled. Certificates scheduled for renewal outside of the windows will be deferred until the current time falls within one of the enabled windows.
Enable System Property: To enable this system property, type "true" for "enabled" in the first part of the Value text area in the Modify System Property dialog box. See image below for an example. Operators can define multiple windows to restrict the days and hours of the day during which edge renewals are enabled. Each window can be defined by a day, or list of days (separated by a comma), and a start and end time. Start and end times can be specified relative to an edge's local timezone, or relative to UTC. See image below for an example. 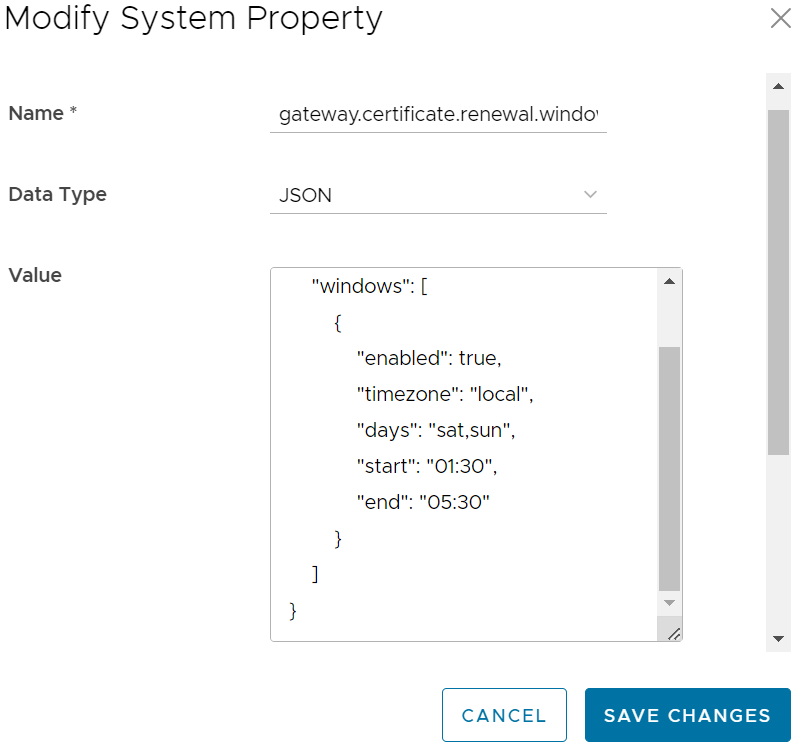 Note: If attributes are not present, the default is enabled
false.When defining window attributes, adhere to the following:
If the above-mentioned values are missing, the attribute defaults in each window definition are as follow:
Deactivate System Property This system property is deactivated by default, which means the certificate will automatically renew after it expires. "Enabled" will be set to "false in the first part of the Value text area in the Modify System Property dialog box. An example of this property when it is deactivated is shown below. {
"enabled": false,
"windows": [
{
Note: This system property requires that PKI be enabled.
|
| System Property | Description |
|---|---|
session.options.enableServiceLicenses |
This system property allows Operator users to manage Service Configuration under , and is set to True, by default. |
| System Property | Description |
|---|---|
retention.highResFlows.days |
This system property enables Operators to configure high resolution flow stats data retention anywhere between 1 and 90 days. |
retention.lowResFlows.months |
This system property enables Operators to configure low resolution flow stats data retention anywhere between 1 and 365 days. |
session.options.maxFlowstatsRetentionDays |
This property enables Operators to query more than two weeks of flows stats data. |
retentionWeeks.enterpriseEvents |
Enterprise events retention period (-1 sets retention to the maximum time period allowed) |
retentionWeeks.operatorEvents |
Operator events retention period (-1 sets retention to the maximum time period allowed) |
retentionWeeks.proxyEvents |
Proxy events retention period (-1 sets retention to the maximum time period allowed) |
retentionWeeks.firewallLogs |
Firewall logs retention period (-1 sets retention to the maximum time period allowed) |
retention.linkstats.days |
Link stats retention period (-1 sets retention to the maximum time period allowed) |
retention.linkquality.days |
Link quality events retention period (-1 sets retention to the maximum time period allowed) |
retention.healthstats.days |
Edge health stats retention period (-1 sets retention to the maximum time period allowed) |
retention.pathstats.days |
Path stats retention period (-1 sets retention to the maximum time period allowed) |
| SD-WAN Data | Date Retention Period |
|---|---|
| Enterprise Events | 1 year |
| Enterprise Alerts | 1 year |
| Operator Events | 1 year |
| Enterprise Proxy Events | 1 year |
| Link Stats | 1 year |
| Link QoE | 1 year |
| Path Stats | 2 weeks |
| Flow Stats (Low Resolution) | 1 year – 1 hour rollup |
| Flow Stats (High Resolution) | 2 weeks – 5 minute rollup |
| Edge Health Stats | 1 year |
| System Property | Description |
|---|---|
edge.offline.limit.sec |
If the Orchestrator does not detect a heartbeat from an Edge for the specified duration, then the state of the Edge is moved to OFFLINE mode. |
edge.link.unstable.limit.sec |
When the Orchestrator does not receive link statistics for a link for the specified duration, the link is moved to UNSTABLE mode. |
edge.link.disconnected.limit.sec |
When the Orchestrator does not receive link statistics for a link for the specified duration, the link is disconnected. |
edge.deadbeat.limit.days |
If an Edge is not active for the specified number of days, then the Edge is not considered for generating Alerts. |
vco.operator.alert.edgeLinkEvent.enable |
Globally activates or deactivates Operator Alerts for Edge Link events. |
vco.operator.alert.edgeLiveness.enable |
Globally activates or deactivates Operator Alerts for Edge Liveness events. |
| System Property | Description |
|---|---|
edge.activation.key.encode.enable |
Base64 encodes the activation URL parameters to obscure values when the Edge Activation Email is sent to the Site Contact. |
edge.activation.trustedIssuerReset.enable |
Resets the trusted certificate issuer list of the Edge to contain only the Orchestrator Certificate Authority. All TLS traffic from the edge are restricted by the new issuer list. |
network.public.certificate.issuer |
Set the value of network.public.certificate.issuer equal to the PEM encoding of the issuer of Orchestrator server certificate, when edge.activation.trustedIssuerReset.enable is set to True. This will add the server certificate issuer to the trusted issuer of the Edge, in addition to the Orchestrator Certificate Authority. |
| System Property | Description |
|---|---|
edge.link.show.limit.sec |
Allows to set the Edge Link Down Limit value for each Edge. |
| System Property | Description |
|---|---|
ntics.public
address |
Specifies the hostname that is used to access the NSX Threat Intelligent Cloud Service (NTICS). |
gsm.public.address |
Specifies the Public address of Global Services Manager (GSM). |
gsm.authentication.key |
Specifies the mTLS key to authenticate with GSM. |
gsm.authentication.cert |
Specifies the mTLS certificate to authenticate with GSM. |
gsm.authentication.passphrase |
Specifies the mTLS passphrase to authenticate with GSM. |
| System Property | Description |
|---|---|
session.options.enableLansidePortRules |
Allows to configure the parameters Inside Port and Outside Port under for an Edge or Profile. |
| System Property | Description |
|---|---|
vco.monitor.enable |
Globally activates or deactivates monitoring of Enterprise and Operator entity states. Setting the Value to False prevents Orchestrator from changing entity states and triggering alerts. |
vco.enterprise.monitor.enable |
Globally activates or deactivates monitoring of Enterprise entity states. |
vco.operator.monitor.enable |
Globally activates or deactivates monitoring of Operator entity states. |
| System Property | Description |
|---|---|
edge.liveData.enterFlowLiveMode.delay.seconds |
How long the Edge waits before giving up on capturing the count configured by edge.liveData.enterFlowLiveMode.delay.seconds. The default value is five seconds. The allowed range is 5- 59 seconds. The invalid input defaults to zero seconds. |
edge.liveData.enterFlowLiveMode.flow.count |
How many flows the Edge will return if met within the configured time controlled by edge.liveData.enterFlowLiveMode.flow.count. The default value is 1000. The allowed range is 1000- 4999 total flows. The invalid input defaults to one flow. |
| System Property | Description |
|---|---|
vco.notification.enable |
Globally activates or deactivates the delivery of Alert notifications to both Operator and Enterprises. |
vco.enterprise.notification.enable |
Globally activates or deactivates the delivery of Alert notifications to the Enterprises. |
vco.operator.notification.enable |
Globally activates or deactivates the delivery of Alert notifications to the Operator. |
| System Property | Description |
|---|---|
vco.object.groups.max.count.per.enterprise |
Maximum allowed number of object groups per Enterprise. The default value is 2000. |
vco.object.groups.max.count.per.edge |
Maximum allowed number of object group associations per Edge and its Profile. The default value is 1000. |
| System Property | Description |
|---|---|
vco.enterprise.resetPassword.token.expirySeconds |
Duration of time, after which the password reset link for an enterprise user expires. |
vco.enterprise.authentication.passwordPolicy |
Defines the password strength, history, and expiration policy for customer users.
Edit the JSON template in the Value field to define the following: strength
Since the new password only varies by 3 characters from the old, “sitting” would be rejected as a new password to replace “kitten”. The default value of-1 signifies that this feature is not enabled. expiry:
history:
|
enterprise.user.lockout.defaultAttempts |
Number of times the enterprise user can attempt to login. If the login fails for the specified number of times, the account is locked. |
enterprise.user.lockout.defaultDurationSeconds |
Duration of time, in seconds, in which the Enterprise user account is locked.
For example, if set to 300, the Enterprise user account will get locked if four incorrect login attempts are made within 300 seconds. If set to 60, the Enterprise user account will get locked if four incorrect attempts are made within one minute. Note: The number of attempts is configurable via the enterprise.user.lockout.defaultAttempts system property.
|
enterprise.user.lockout.enabled |
Activates or deactivates the lockout option for the enterprise login failures. |
vco.operator.resetPassword.token.expirySeconds |
Duration of time, after which the password reset link for an Operator user expires. |
vco.operator.authentication.passwordPolicy |
Defines the password strength, history, and expiration policy for Operator users.
Edit the JSON template in the Value field to define the following: strength
Since the new password only varies by 3 characters from the old, “sitting” would be rejected as a new password to replace “kitten”. The default value of-1 signifies that this feature is not enabled. expiry:
history:
|
operator.user.lockout.defaultAttempts |
Number of times the Operator user can attempt to login. If the login fails for the specified number of times, the account is locked. |
operator.user.lockout.defaultDurationSeconds |
Duration of time, in seconds, in which an Operator user account is locked.
For example, if set to 300, the Operator user account will get locked if four incorrect login attempts are made within 300 seconds. If set to 60, the Operator user account will get locked if four incorrect attempts are made within one minute. Note: The number of attempts is configurable via the operator.user.lockout.defaultAttempts system property.
|
operator.user.lockout.enabled |
Activates or deactivates the lockout option for the Operator login failures. |
| System Property | Description |
|---|---|
vco.api.rateLimit.enabled |
Allows Operator Super users activate or deactivate the rate limiting feature at the system level. By default, the value is False.
Note: The rate-limiter is not enabled in earnest, that is, it will not reject API requests that exceed the configured limits, unless the vco.api.rateLimit.mode.logOnly setting is deactivated.
|
vco.api.rateLimit.mode.logOnly |
Allows Operator Super user to use rate limit in a LOG_ONLY mode. When the value is set as True and if a rate limit exceeds, this option logs only the error and fires respective metrics allowing clients to make requests without rate limiting.
When the value is set to False, the request API is restricted with defined policies and HTTP 429 is returned. |
vco.api.rateLimit.rules.global |
Allows to define a set of globally applicable policies used by the rate-limiter, in a JSON array. By default, the value is an empty array.
Each type of user (Operator, Partner, and Customer) can make up to 500 requests for every 5 seconds. The number of requests is subject to change based on the behavior pattern of the rate limited requests. The JSON array consists of the following parameters: Types: The type objects represent different contexts in which the rate limits are applied. The following are the different type objects that are available:
Policies: Add rules to the policies to apply the requests that match the rule, by configuring the following parameters:
Enabled: Each type limit can be activated or deactivated by including the enabled key in APIRateLimiterTypeObject. By default, the value of enabled is True, even if the key is not included. You need to include "enabled": false key to deactivate the individual type limits. The following example shows a sample JSON file with default values: Note: It is recommended not to change the default values of the configuration parameters.
|
vco.api.rateLimit.rules.enterprise.default |
Comprises the default set of Enterprise-specific policies applied to newly created Customers. The Customer-specific properties are stored in the Enterprise property vco.api.rateLimit.rules.enterprise. |
vco.api.rateLimit.rules.enterpriseProxy.default |
Comprises the default set of Enterprise-specific policies applied to newly created Partners. The Partner-specific properties are stored in the Enterprise proxy property vco.api.rateLimit.rules.enterpriseProxy. |
| System Property | Description |
|---|---|
network.public.address |
Specifies the browser origin address/DNS hostname that is used to access the Orchestrator UI. |
network.portal.websocket.address |
Allows to set an alternate DNS hostname/address to access the Orchestrator UI from a browser, if the browser address is not the same as the value of network.public.address system property.
As remote diagnostics now uses a WebSocket connection, to ensure web security, the browser origin address that is used to access the Orchestrator UI is validated for incoming requests. In most cases, this address is same as the network.public.address system property. In rare scenarios, the Orchestrator UI can be accessed using another DNS hostname/address that is different from the value set in the network.public.address system property. In such cases, you can set this system property to the alternate DNS hostname/address. By default, this value is not set. |
session.options.websocket.portal.idle.timeout |
Allows to set the total amount of time (in seconds) the browser WebSocket connection is active in an idle state. By default, the browser WebSocket connection is active for 300 seconds in an idle state. |
| System Property | Description |
|---|---|
session.options.enableSseService |
Activates or deactivates the Security Service Edge (SSE) feature for Enterprise users. |
| System Property | Description |
|---|---|
enterprise.capability.enableSegmentation |
Activates or deactivates the segmentation capability for Enterprise users. |
enterprise.segments.system.maximum |
Specifies the maximum number of segments allowed for any Enterprise user. Ensure that you change the value of this system property to 128 if you want to enable 128 segments on Orchestrator for an Enterprise user. |
enterprise.segments.maximum |
Specifies the default value for the maximum number of segments allowed for a new or existing Enterprise user. The default value for any Enterprise user is 16.
Note: This value must be less than or equal to the number defined in the system property, enterprise.segments.system.maximum.
It is not recommended for you to change the value of this system property if you want to enable 128 segments for an Enterprise user. Instead, you can enable Customer Capabilities in the Customer Configuration page to configure the required number of segments. |
enterprise.subinterfaces.maximum |
Specifies the maximum number of sub-interfaces that can be configured for an Enterprise user. The default value is 32. |
enterprise.vlans.maximum |
Specifies the maximum number of VLANs that can be configured for an Enterprise user. The default value is 32. |
session.options.enableAsyncAPI |
When the segment scale is increased to 128 segments for any Enterprise user, to prevent UI timeouts, you can enable Async APIs support on the UI by using this system property. The default value is true. |
session.options.asyncPollingMilliSeconds |
Specifies the Polling interval for Async APIs on the UI. The default value is 5000 milliseconds. |
session.options.asyncPollingMaxCount |
Specifies the maximum number of calls to get Status API from the UI. The default value is 10. |
vco.enterprise.events.configuration.diff.enable |
Activates or deactivates configuration diff event logging. Whenever the number of segments for an Enterprise user is greater than 4, the configuration diff event logging will be deactivated. You can enable configuration diff event logging using this system property. |
| System Property | Description |
|---|---|
vco.enterprise.resetPassword.twoFactor.mode |
Defines the mode for the second level for password reset authentication, for all the Enterprise users. Currently, only the SMS mode is supported. |
vco.enterprise.resetPassword.twoFactor.required |
Activates or deactivates the two-factor authentication for password reset of Enterprise users. |
vco.enterprise.selfResetPassword.enabled |
Activates or deactivates self-service password reset for Enterprise users. |
vco.enterprise.selfResetPassword.token.expirySeconds |
Duration of time, after which the self-service password reset link for an Enterprise user expires. |
vco.operator.resetPassword.twoFactor.required |
Activates or deactivates the two-factor authentication for password reset of Operator users. |
vco.operator.selfResetPassword.enabled |
Activates or deactivates self-service password reset for Operator users. |
vco.operator.selfResetPassword.token.expirySeconds |
Duration of time, after which the self-service password reset link for an Operator user expires. |
| System Property | Description |
|---|---|
log.syslog.backend |
Backend service syslog integration configuration. |
log.syslog.portal |
Portal service syslog integration configuration. |
log.syslog.upload |
Upload service syslog integration configuration. |
log.syslog.lastFetchedCRL.backend |
Keeps the last updated CRL as PEM formatted string for service syslog and updated regularly. |
log.syslog.lastFetchedCRL.portal |
Keeps the last updated CRL as PEM formatted string for service syslog and updated regularly. |
log.syslog.lastFetchedCRL.upload |
Keeps the last updated CRL as PEM formatted string for service syslog and updated regularly. |
| System Property | Description |
|---|---|
session.options.enableTACACS |
Activates or deactivates the TACACS services for Enterprise users. |
| System Property | Description |
|---|---|
vco.enterprise.authentication.twoFactor.enable |
Activates or deactivates the two-factor authentication for Enterprise users. |
vco.enterprise.authentication.twoFactor.mode |
Defines the mode for the second level authentication for Enterprise users. Currently, only SMS is supported as the second level authentication mode. |
vco.enterprise.authentication.twoFactor.require |
Defines the two-factor authentication as mandatory for Enterprise users. |
vco.operator.authentication.twoFactor.enable |
Activates or deactivates the two-factor authentication for Operator users. |
vco.operator.authentication.twoFactor.mode |
Defines the mode for the second level authentication for Operator users. Currently, only SMS is supported as the second level authentication mode. |
vco.operator.authentication.twoFactor.require |
Defines the two-factor authentication as mandatory for Operator users. |
| System Property | Description |
|---|---|
session.options.enableNsdPkiIPv6Config |
Activates Certificate Authentication mode and IPv6 Local Identification Type. |
| System Property | Description |
|---|---|
edge.vnf.extraImageInfos |
Defines the properties of a VNF Image.
You can enter the following information for a VNF Image, in JSON format in the Value field:
Example of a JSON file for Check Point Firewall Image:
Example of a JSON file for Fortinet Firewall Image:
|
edge.vnf.metric.record.limit |
Defines the number of records to be stored in the database. |
enterprise.capability.edgeVnfs.enable |
Allows VNF deployment on supported Edge models. |
enterprise.capability.edgeVnfs.securityVnf.checkPoint |
Activates Check Point Networks Firewall VNF. |
enterprise.capability.edgeVnfs.securityVnf.fortinet |
Activates Fortinet Networks Firewall VNF. |
enterprise.capability.edgeVnfs.securityVnf.paloAlto |
Activates Palo Alto Networks Firewall VNF. |
session.options.enableVnf |
Activates VNF feature. |
vco.operator.alert.edgeVnfEvent.enable |
Activates or deactivates Operator alerts for Edge VNF events globally. |
vco.operator.alert.edgeVnfInsertionEvent.enable |
Activates or deactivates Operator alerts for Edge VNF Insertion events globally. |
edge.vnf.extraImageInfos. |
Allows selection of the Check Point VNF image. |
| System Property | Description |
|---|---|
vpn.disconnect.wait.sec |
The time interval for the system to wait before disconnecting a VPN tunnel. |
vpn.reconnect.wait.sec |
The time interval for the system to wait before reconnecting a VPN tunnel. |
| System Property | Description |
|---|---|
login.warning.banner.message |
This optional system property allows the Operator to configure and display a Security Administrator-specified advisory notice and consent warning message regarding the use of Orchestrator. The warning message is displayed in the Orchestrator prior to user login.
For instructions about how to configure this system property, see the topic Configure Advisory Notice and Consent Warning Message for SD-WAN Orchestrator. |
| System Property | Description |
|---|---|
session.options.enableZscalerProfileAutomation |
Enables to configure Zscaler settings at the Profile level. |
This section provides disaster recovery (DR) instructions for Orchestrator.
The Orchestrator Disaster Recovery (DR) feature prevents the loss of stored data and resumes Orchestrator services in the event of system or network failure.
In a Orchestrator DR deployment, two identical Orchestrator systems are configured as an active / standby pair. The operator can view the state of DR readiness through the web UI on either of the servers. Edges and Gateways are aware of both Orchestrators, and while they receive configuration changes only from the active Orchestrator, they periodically send DR heartbeats to both systems to report their view of both servers and to query the DR system status. When the operator triggers a failover, the Edges and Gateways are informed of the change in their next DR heartbeat.
From the view of an operator, and of the edges and gateways, a Orchestrator has one of four DR states:
| DR State | Description |
|---|---|
| Standalone | No DR configured. |
| Active | DR configured, acting as the primary Orchestrator server. |
| Standby | DR configured, acting as an inactive replica Orchestrator server. |
| Zombie | DR formerly configured and active but no longer acting as the active or standby. |
When DR is configured, the standby server runs in a limited mode, blocking all API calls except those related to the DR status and the DR heartbeats. When the operator invokes a failover, the standby is promoted to become fully operational as a Standalone server. The server that was formerly active is automatically transitioned to a Zombie state if it is responsive and visible from the promoted standby. In the Zombie state, management configuration services are blocked and any contact from Edges and Gateways that have not transitioned to the new active Orchestrator are redirected to the promoted server.

STANDBY_CANDIDATE state, enabling it to be configured by the active server.ACTIVE_CONFIGURING state.When a STANDBY_CONFIG_RQST is created from Active to Standby, the two servers synchronize through the state transitions.
vcadmin@vcg1-example:~$ cat /etc/timezone
Etc/UTC
vcadmin@vcg1-example:~$If the time zone is incorrect, use the following commands to update the time zone.
echo "Etc/UTC" | sudo tee /etc/timezone
sudo dpkg-reconfigure --frontend noninteractive tzdatasudo ntpqvcadmin@vcg1-example:~$ sudo ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*ntp1-us1.prod.v 74.120.81.219 3 u 474 1024 377 10.171 -1.183 1.033
ntp1-eu1-old.pr .INIT. 16 u - 1024 0 0.000 0.000 0.000
vcadmin@vcg1-example:~$If the offset is incorrect, use the following commands to update the NTP offset.
sudo systemctl stop ntp
sudo ntpdate <server>
sudo systemctl start ntp/etc/ntpd.conf file. The Orchestrators on which DR need to be established must have Internet to access the default NTP Servers and ensure the time is in sync on both the Orchestrators. Customers can also use their local NTP server running in their environment to sync time.To set up Orchestrator replication, perform the following steps:
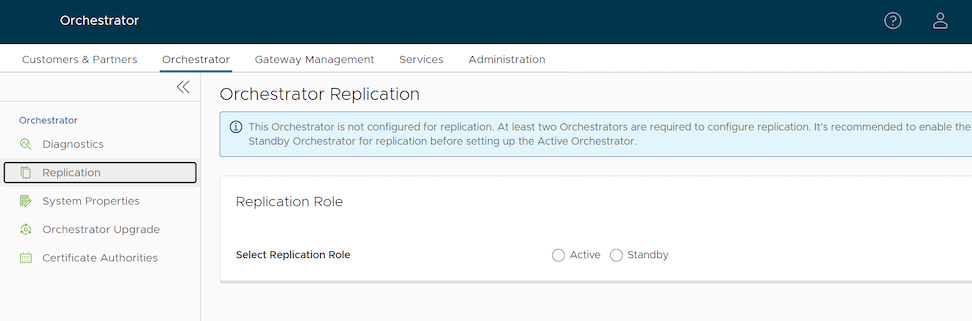
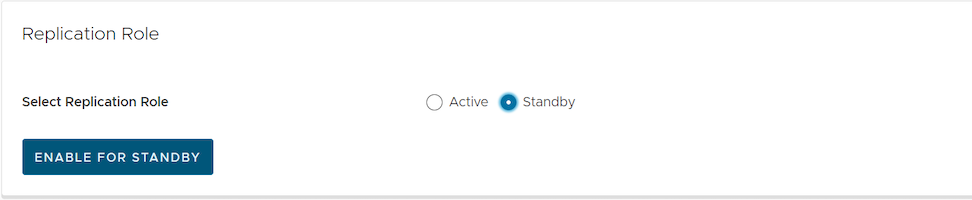


After configuring the Standby Orchestrator for replication, configure the Active Orchestrator.
Configure the second Orchestrator to be the Active Orchestrator:
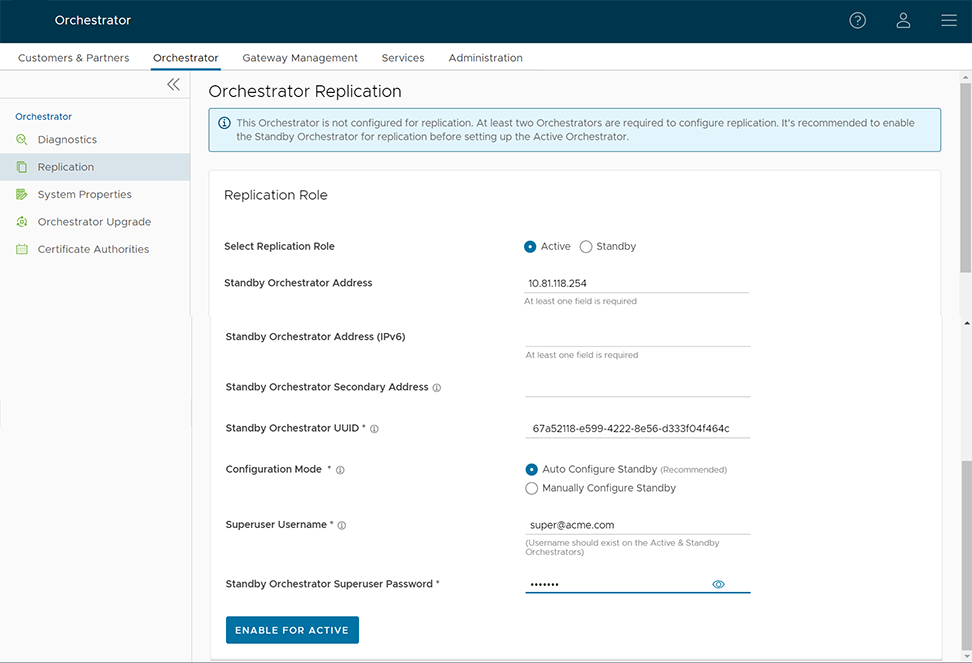
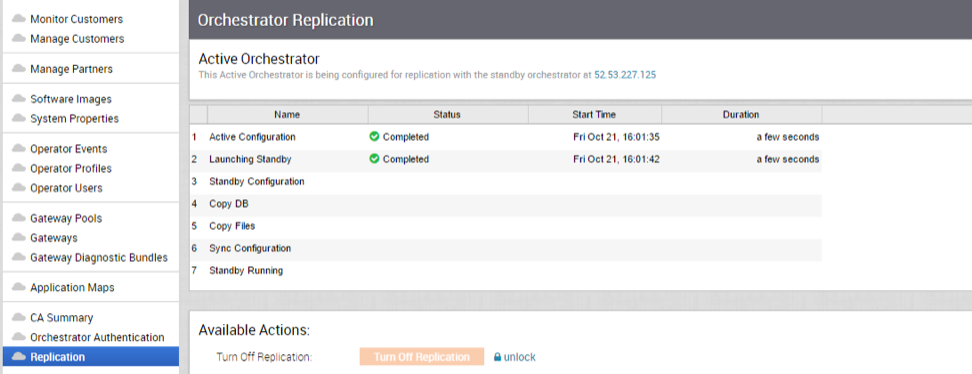
When configuration is complete, both Orchestrators (Standby and Active) will be in sync.

You can select the toggle history link to view the status of each state.

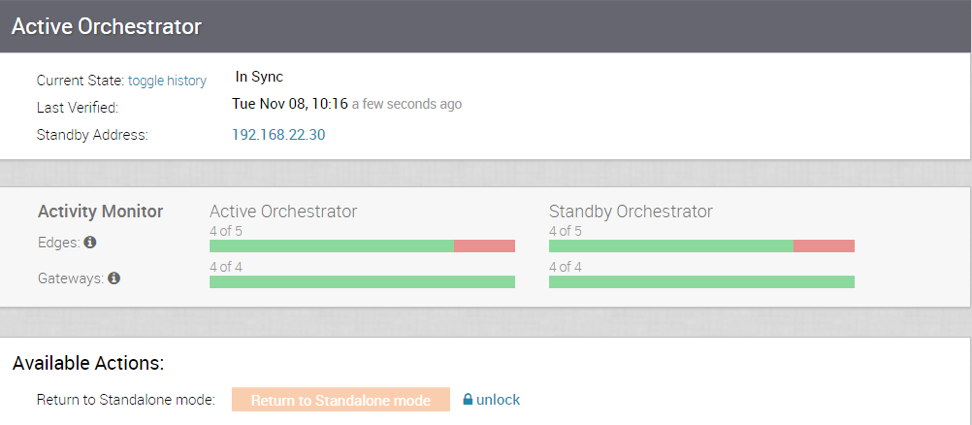
The following testing failover scenarios are forced failovers for example purposes. You can perform these actions in the Available Actions area of the Active and Standby screens.
This section discusses how to promote a Standby Orchestrator.
To promote a Standby Orchestrator, perform the following steps:

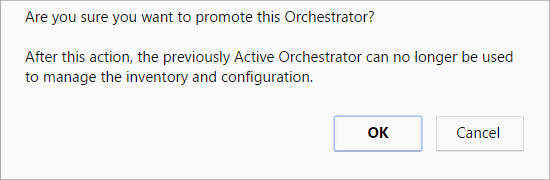
The following dialog box appears, indicating that when you promote your Standby Orchestrator, administrators will no longer be able to manage the Orchestrator using the previously Active Orchestrator.

A final dialog box appears indicating that the Orchestrator is no longer a Standby and will restart in Standalone mode.

When you promote a Standby Orchestrator, it restarts in Standalone mode.
If the Standby can communicate with the formerly Active Orchestrator, it instructs the Orchestrator to enter a Zombie state. In Zombie state, the Orchestrator communicates with its clients (edges, gateways, UI/API) that it is no longer active, and that they must communicate with the newly promoted Orchestrator. If the promoted Standby cannot communicate with the formerly Active Orchestrator, the operator should, if possible, manually demote the formerly Active Orchestrator.
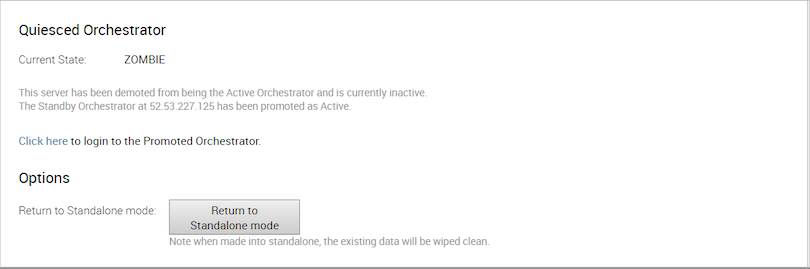
To return the Zombie to standalone mode, select Return to Standalone Mode in the Available Actions area on the Active Orchestrator or Standby Orchestrator screens.

vco.disasterRecovery.zombie.expirySeconds which defaults to 1800 seconds.This section describes the failure states of the system. These are also listed in the UI, along with a more detailed description of the failure. Additional information is available in the VeloCloud log.
FAILURE_SYNCING_FILESFAILURE_GET_STANDBY_STATUSFAILURE_MYSQL_ACTIVE_STATUSFAILURE_MYSQL_STANDBY_STATUSFAILURE_ACTIVE_CONFIGURINGFAILURE_LAUNCHING_STANDBYFAILURE_STANDBY_CONFIGURINGFAILURE_COPYING_DBFAILURE_COPYING_FILESFAILURE_SYNC_CONFIGURINGFAILURE_GET_STANDBY_CONFIGFAILURE_STANDBY_CANDIDATEFAILURE_STANDBY_UNCONFIGFAILURE_STANDBY_PROMOTIONFAILURE_ACTIVE_DEMOTIONThe Orchestrator Disaster Recovery (DR) feature prevents the loss of stored data and resumes Orchestrator services in the event of system or network failure.
In a Orchestrator DR deployment, two identical Orchestrator systems are configured as an active / standby pair. The operator can view the state of DR readiness through the web UI on either of the servers. Edges and gateways are aware of both Orchestrators, and while they receive configuration changes only from the active Orchestrator, they periodically send DR heartbeats to both systems to report their view of both servers and to query the DR system status. When the operator triggers a failover, the Edges and Gateways are informed of the change in their next DR heartbeat.
From the view of an operator, and the Edges and Gateways, a Orchestrator has one of the following four DR states:
| DR State | Description |
|---|---|
| Standalone | No DR configured. |
| Active | DR configured, acting as the primary Orchestrator server. |
| Standby | DR configured, acting as an inactive replica Orchestrator server. |
| Zombie | DR formerly configured and active but no longer acting as the active or standby. |
When DR is configured, the standby server runs in a limited mode, blocking all API calls except those related to the DR status and the DR heartbeats. When the operator invokes a failover, the standby is promoted to become fully operational as a Standalone server. The server that was formerly active is automatically transitioned to a Zombie state if it is responsive and visible from the promoted standby. In the Zombie state, management configuration services are blocked and any contact from edges and gateways that have not transitioned to the new active Orchestrator are redirected to the promoted server.
STANDBY_CANDIDATE state, enabling it to be configured by the active server.ACTIVE_CONFIGURING state.When a STANDBY_CONFIG_RQST is made from active to standby, the two servers synchronize through the state transitions.
vcadmin@vcg1-example:~$ cat /etc/timezone
Etc/UTC
vcadmin@vcg1-example:~$If the time zone is incorrect, use the following commands to update the time zone.
echo "Etc/UTC" | sudo tee /etc/timezone
sudo dpkg-reconfigure --frontend noninteractive tzdatasudo ntpqvcadmin@vcg1-example:~$ sudo ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*ntp1-us1.prod.v 74.120.81.219 3 u 474 1024 377 10.171 -1.183 1.033
ntp1-eu1-old.pr .INIT. 16 u - 1024 0 0.000 0.000 0.000
vcadmin@vcg1-example:~$If the offset is incorrect, use the following commands to update the NTP offset.
sudo systemctl stop ntp
sudo ntpdate <server>
sudo systemctl start ntp
The Standby Orchestrator page appears.
After the Standby Orchestrator has been configured for replication, configure the Active Orchestrator according to the instructions below.
To set up the Active Orchestrator, select the Replication Role as Active and configure the following:

| Option | Description |
|---|---|
| Select Replication Role | Select the Active radio button for the replication role. |
| Standby Orchestrator Address | Enter the primary Standby Orchestrator IP Address. |
| Standby Orchestrator Address (IPv6) | Enter the Standby Orchestrator IPv6 Address. |
| Standby Orchestrator Secondary Address | Enter the address of the standby Orchestrator's secondary interface. This address is used for replication if the standby is promoted to active. Users can add Ipv4/Ipv6 or FQDN address here. |
| Standby Orchestrator UUID | Enter the UUID of the standby Orchestrator. |
| Configuration Mode | Select the Auto Configure Standby or Manually Configure Standby radio button based on the requirement.
When configured manually, paste a string value from ACTIVE VCO to STANDBY_WAIT . |
| Superuser Username | Enter the display name for the Orchestrator Superuser. |
| Standby Orchestrator Superuser Password | Enter the password for the Orchestrator Superuser.
Note: Starting from the 4.5 release, the use of the special character "<" in the password is no longer supported. In cases where users have already used "<" in their passwords in previous releases, they must remove it to save any changes on the page.
|
When configuration is complete, both Orchestrators (Standby and Active) are in sync.
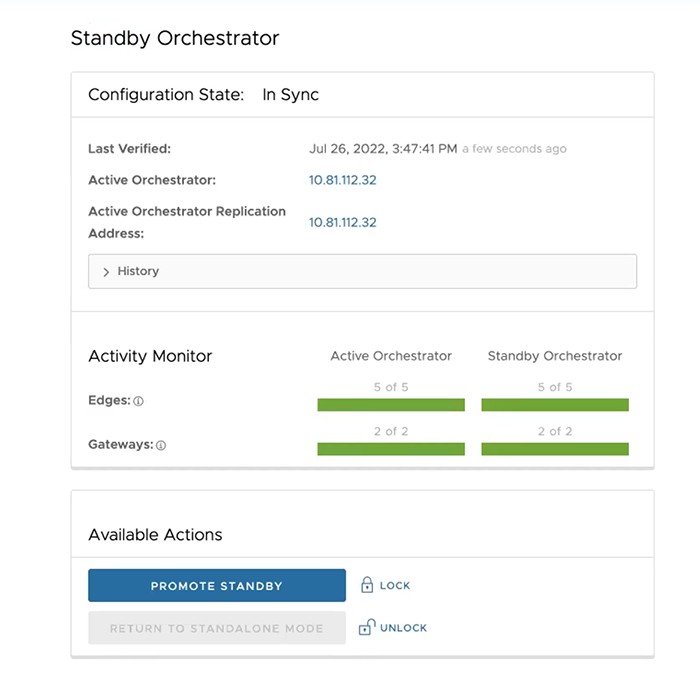
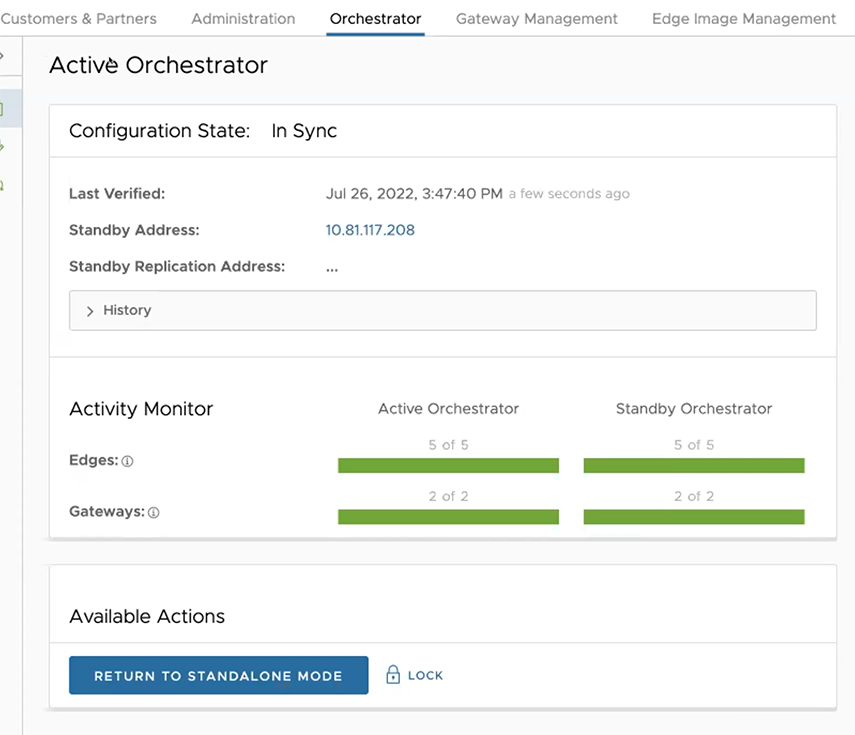
The following testing failover scenarios are forced failovers for example purposes. You can perform these actions in the Available Actions area of the Active and Standbyscreens.
This section discusses how to promote a Standby Orchestrator.

The following dialog box appears, indicating that when you promote your Standby Orchestrator, administrators can no longer be able to manage the Orchestrator using the previously Active Orchestrator.
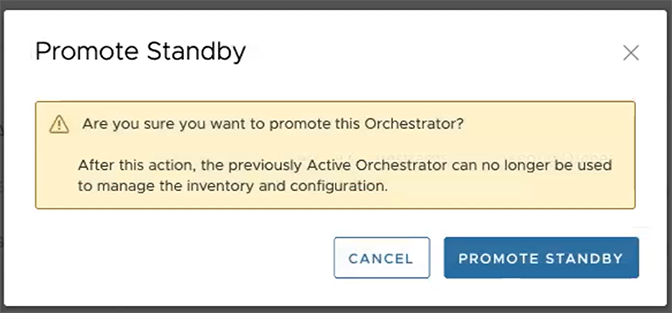
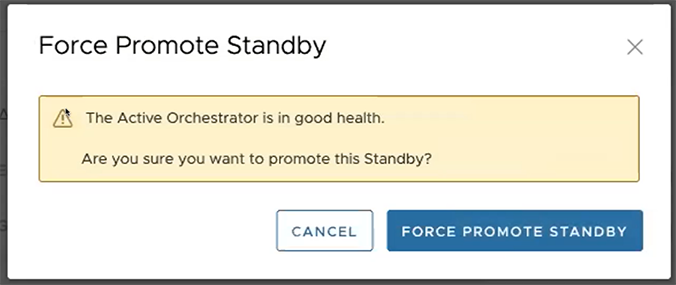
A final dialog box appears indicating that the Orchestrator is no longer a Standby and restarts in Standalone mode.

When you promote a Standby Orchestrator, it restarts in Standalone mode.
If the Standby can communicate with the formerly Active Orchestrator, it instructs that Orchestrator to enter a Zombie state. In Zombie state, the Orchestrator communicates with its clients (edges, gateways, UI/API) that it is no longer active, and that they must communicate with the newly promoted Orchestrator. If the promoted Standby cannot communicate with the formerly Active Orchestrator, the operator should, if possible, manually demote the formerly Active Orchestrator.
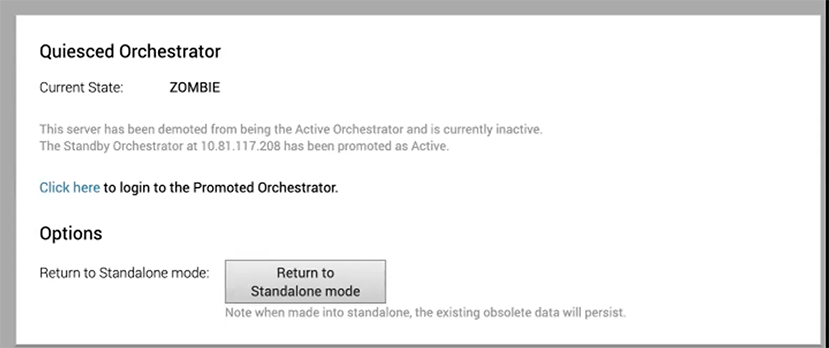
To return the Zombie to standalone mode, select the Return to Standalone Mode button in the Available Actions area on the Active Orchestrator or Standby Orchestrator screens.
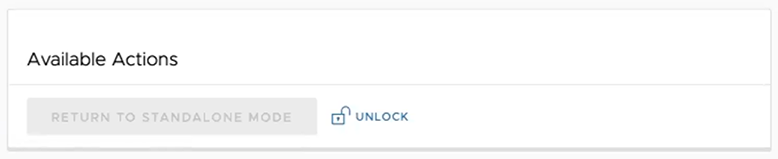
The Orchestrator can be returned to the Standalone mode from the Zombie state after the time specified in the system property "vco.disasterRecovery.zombie.expirySeconds," which is defaulted to 1800 seconds.
This section discusses the failure states of the system. These are also listed in the UI, along with a more detailed description of the failure. Additional information is available in the Arista log.
This section discusses how to upgrade the Orchestrator.
This section discusses how to upgrade an Orchestrator.
Contact Arista Support team to prepare for the Orchestrator upgrade.
To upgrade Orchestrator:

/var/log
tar -czf /store/log-`date +%Y%M%S`.tar.gz
--newer-mtime="36 hours ago"
/var/logsudo mysql
--defaults-extra-file=/etc/mysql/velocloud.cnf
velocloud -e 'SHOW SLAVE STATUS \G'sudo mysql
--defaults-extra-file=/etc/mysql/velocloud.cnf velocloud
-e 'SHOW MASTER STATUS \G'The Upgrade Announcement area enables you to configure and send a message about an upcoming upgrade. This message will be displayed to all users the next time they login to the Orchestrator.

(Optional) You can remove the announcement from the Orchestrator by selecting Unannounce Orchestrator Upgrade. A message appears indicating you successfully unannounced the Orchestrator upgrade. The announcement displayed at the top of the Orchestrator disappears.
This section provides important information to consider prior to upgrading the Orchestrator, as well as how the image-based upgrade works. Contact Arista Support to assist you with the 5.4 to 6.0 upgrade.
edge.heartbeat.spread.factor system property. Then, change the heartbeat spread factor to a relatively high value for a large Orchestrator (e.g. 20, 40, 60). This will help reduce the sudden spike of the resource utilization (CPU, IO) on the system. Make sure to verify that all Gateways and Edges are in a connected state before restoring the previous edge.heartbeat.spread.factor value from the System Property page in the Orchestrator.Contact Arista Support at for assistance with the Orchestrator upgrade.
After you have completed the Orchestrator upgrade, select Complete Orchestrator Upgrade. This re-enables the application of the configuration updates of Edges at the global level.
dpkg -l|grep vcoThis section discusses how to set up and upgrade disaster recovery in the Orchestrator.
To set up disaster recovery in the Orchestrator:
vco.disasterRecovery.transientErrorToleranceSecs to a non-zero value (it defaults to 900 seconds in version 3.3 and later, but to zero in earlier versions). This prevents any transient errors from resulting in an Edge/Gateway management plane update.vco.disasterRecovery.mysqlExpireLogsDays (defaults is 1 day). This is the amount of time the Active Orchestrator keeps the mysql
binlog data.network.public.address property on the Active and Standby Orchestrators to the address contacted by the Edges (Heartbeats).dr-standby-schema.sh on the Standby before starting the upgrade.This section discusses Orchestrator troubleshooting.
The Orchestrator Diagnostics bundle is a collection of diagnostic information that is required for Support and Engineering to troubleshoot the Orchestrator. For Orchestrator on-premises installation, Operators can collect the Orchestrator Diagnostic bundle from the Orchestrator UI and provide it to the Arista Support team for offline analysis and troubleshooting.
Users can request and download a diagnostic bundle in the Diagnostics Bundle tab.
The Orchestrator Diagnostics table grid includes the following columns:
| Column Name | Description |
|---|---|
| Request Status | There are two types of status requests:
|
| Reason for Generation | The specific reason given for generating a diagnostic bundle. Select the Request Diagnostic Bundle button to include a description of the bundle. |
| User | The individual logged into the Orchestrator. |
| Generated | The date and time when the diagnostic bundle request was sent. |
| Cleanup Date | The default Cleanup Date is three months after the generated date, when the bundle will be automatically deleted. If you need to extend the Cleanup date period, select the Cleanup Date link located under the Cleanup Date column. For additional information, see Updating Cleanup Date. |
To request a diagnostic bundle:


To download a diagnostic bundle:
The Cleanup date represents the date when the generated bundle will be automatically deleted, which by default is three months after the Generated date. You can change the Cleanup date or choose to keep the bundle indefinitely.
To update the Cleanup date:

The Orchestrator Diagnostics table grid updates to reflect the changes to the Cleanup Date.
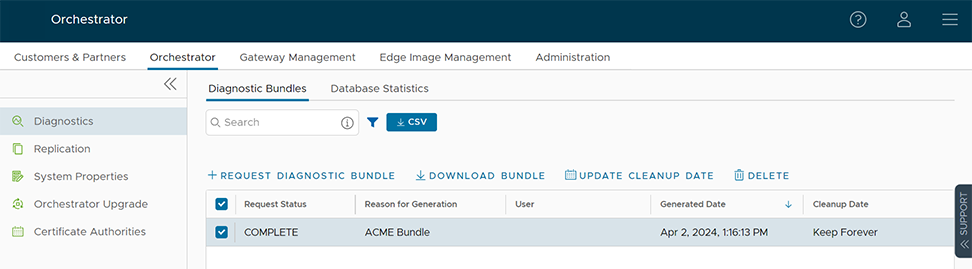
The Database Statistics tab provides a read-only access view of some of the information from a diagnostic bundle.
If you require additional information, go to the Diagnostic Bundles tab, request a diagnostic bundle, and download it locally. For additional information, see Request Diagnostic Bundle.

| Field | Description |
|---|---|
| Database Sizes | Sizes of the Orchestrator databases. |
| Database Table Statistics | Statistical details of all tables in the Orchestrator database. |
| Database Storage Info | Storage details of the mounted locations. |
| Database Process List | The top 20 records of long-running SQL queries. |
| Database Status Variable | The status variables of the MySQL server. |
| Database System Variable | System variables of the MySQL server. |
| Database Engine Status | The InnoDB engine status of the MySQL server. |
This section discusses System Metrics Monitoring on the Orchestrator.
The Orchestrator comes with a built-in system metrics monitoring stack, which includes a metrics collector and a time-series database. With the monitoring stack, you can easily check the health condition and the system load for the Orchestrator.
sudo /opt/vc/scripts/vco_observability_manager.sh enablesudo /opt/vc/scripts/vco_observability_manager.sh statussudo /opt/vc/scripts/vco_observability_manager.sh disable| Metric Name | Description |
|---|---|
| inputs.cpu | Metrics about CPU usage. |
| inputs.mem | Metrics about memory usage. |
| inputs.net | Metrics about network interfaces. |
| inputs.system | Metrics about system load and uptime. |
| inputs.processes | The number of processes grouped by status. |
| inputs.disk | Metrics about disk usage. |
| inputs.diskio | Metrics about disk IO by device. |
| inputs.procstat | CPU and memory usage for specific processes. |
| inputs.nginx | Nginx's basic status information (ngx_http_stub_status_module). |
| inputs.mysql | Statistic data from the MySQL server. |
| inputs.clickhouse | Metrics from one or many ClickHouse servers. |
| inputs.redis | Metrics from one or many redis servers. |
| inputs.filecount | The number and total size of files in specified directories. |
| inputs.ntpq | Standard NTP query metrics (requires ntpq executable). |
| Inputs.x509_cert | Metrics from a SSL certificate. |
Prometheus is used to store the system metrics collected by Telegraf. The metrics data will be kept in the database for three weeks at the most. By default, Prometheus listens on port 9090. If you have an external monitoring tool, provide the Prometheus database as a source, so that you can view the Orchestrator system metrics on your monitoring UI.
When there are too many API requests sent at a time, it affects the performance of the system. You can enable Rate Limiting, which enforces a limit on the number of API requests sent by each user.
The Orchestrator makes use of certain defence mechanisms that curb API abuse and provides system stability. API requests that exceed the allowed request limits are blocked and returned with HTTP 429 (Too many Requests). The system needs to go through a cool down period before making the requests again.
vco.api.rateLimit.enabledvco.api.rateLimit.mode.logOnlyvco.api.rateLimit.rules.globalvco.api.rateLimit.rules.enterprise.defaultvco.api.rateLimit.rules.enterpriseProxy.defaultFor additional information on the system properties, see List of System Properties.
For additional information on the APIs, see VeloCloud API Guide.
This section provides information about the available options to monitor, backup, and upgrade Enterprise On-Premises deployments in a two-day operation scenario.
This approach always requires a significant investment in people and time to manage, operate, and patch properly. The table below outlines some of the elements that must be considered when managing a system on-premises.
| System | Description | VeloCloud Hosted Responsibility | On-Premises Responsibility |
|---|---|---|---|
| SD-WAN Orchestration | Application QoS and link steering policy | Yes | Yes |
| Security policy for apps and SD-WAN appliances | Yes | Yes | |
| SD-WAN appliance provisioning and troubleshooting | Yes | Yes | |
| Handling of SD-WAN alerting & events | Yes | Yes | |
| Link performance and capacity monitoring | Yes | Yes | |
| Hypervisor | Monitoring / alerting | No | Yes |
| Compute and memory resourcing | No | Yes | |
| Virtual networking and storage | No | Yes | |
| Backup | No | Yes | |
| Replication | No | Yes | |
| Infrastructure | CPU, memory, compute | No | Yes |
| Switching and routing | No | Yes | |
| Monitoring & management systems | No | Yes | |
| Capacity planning | No | Yes | |
| Software upgrades/patching | No | Yes | |
| Troubleshooting application/infrastructure issues | No | Yes | |
| Backup and Infrastructure DR | Backup infrastructure | No | Yes |
| Regular testing of backup regime | No | Yes | |
| DR infrastructure | No | Yes | |
| DR testing | No | Yes |
See Day One Operations and Day Two Operations to continue your deployment.
Deactivating the Cloud-init on the Orchestrator
The data-source contains two sections: meta-data and user-data. Meta-data includes the instance ID and should not change during the lifetime of the instance, while user-data is a configuration applied on the first boot (for the instance ID in meta-data).
It is not recommended to purge the cloud-init file with the command apt
purge cloud-init (this procedure does not cause issues in the VeloCloud SD-WAN Controller). Purging the cloud-init file also erases some essential Orchestrator tools and scripts such as upgrade and backup scripts. If the purge command was used, you can restore the files using the following commands:
The expectation is that the NTP offset is <= 15 milliseconds.
When the Orchestrator is initially deployed, three partitions are created: /, /store, /store2, /store3 (version 4.0 and onward). The partitions are created with default sizes. Follow the instructions in Increasing Storage in the Orchestrator for guidance in modifying the default sizes to match the design.
This section provides the available mechanisms to periodically backup the Orchestrator database to recover from Operator errors or catastrophic failure of both the Active and Standby Orchestrator.
Remember that the Disaster Recovery feature or DR is the preferred recovery method. It provides a Recovery Point Objective of nearly zero, as all configurations on the Active Orchestrator is instantly replicated. For more details on the Disaster recovery feature, refer to the next section.
Backup Using the Embedded Script
The Orchestrator provides an in-built configuration backup mechanism to periodically Backup the configuration to recover from Operator errors or catastrophic failure of both the Active and Standby Orchestrator. The mechanism is script-driven and is located at /opt/vc/scripts/db_backup.sh.
The script essentially takes a database dump of the configuration data and events, while excluding some of the large monitoring tables during the database dump process. Once the script is executed, backup files are created in the local directory path provided as input to the above script.
The Backup consists of two .gzs files, one containing the database schema definition and the other one containing the actual data without definition. The administrator should ensure that the backup directory location has enough disk space for the Backup.
The duration of the Backup depends on the scale of the actual customer configuration. Since the monitoring tables are excluded from the Backup operation, it is expected that the configuration Backup operation will complete quickly. For a large Orchestrator with thousands of Edge and lots of historical events, it could take up to an hour, while a smaller Orchestrator should be completed within a few minutes.
Depending on the size and time it takes to complete the initial backup, the Backup operation frequency can be determined. The Backup operation should be scheduled to run during off-peak hours to reduce the impact on Orchestrator resources.
It is recommended that other mounted volumes are used to store the backup. Note, it is not a best practice to use the root filesystem for the backup.
The script stdout and stderr should be sufficient to determine the success or failure of the Backup operation. If the script invocation is automated, the exit code can determine the Backup operation's success or failure.
Currently, Arista requires that the customer work with Arista Support to recover the configuration data. Arista Support will help to recover the customer's configuration. Customers should refrain from making any additional configuration changes until the configuration is restored.
Even though a backup of the configuration should have little impact on performance, there will be an increase in resource utilization for the MySQL process. It is recommended that the Backup be run during off-peak hours.
It is safe to make configuration changes while the Backup operation is running. However, to ensure up-to-date backups, it is recommended that no configuration operations are done while the Backup is running.
Yes, the configuration can, and ideally should, be restored on the same Orchestrator if it is available. This will ensure that the monitoring data is utilized after the Restore operation is completed. If the original Orchestrator cannot be recovered and the Standby Orchestrator is down, the configuration can be restored on a new Orchestrator. In this instance, the monitoring data will be lost.
Please contact Arista Support for the recommended set of actions on the new Orchestrator as the steps vary depending on the actual deployment.
No, Edges are not required to register on the new Orchestrator, as all needed information is preserved as part of the Backup.
The Orchestrator Disaster Recovery (DR) feature prevents the loss of stored data and resumes Orchestrator services in the event of system or network failure. Orchestrator DR involves setting up an Active/Standby Orchestrator pair with data replication and a manually-triggered failover mechanism.
See Set Up Orchestrator Disaster Recovery for detailed instructions.
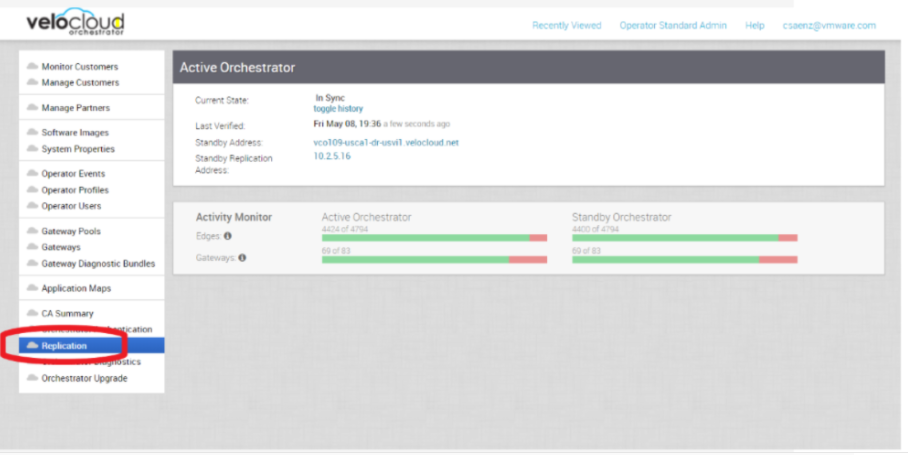
One of the customer's responsibilities on enterprise On-Prem deployments is to monitor the solution. Monitoring gives customer's the visibility required to be one step ahead of possible issues.
SD-WAN Controller Monitoring
You can monitor the status and usage data of Controllers available in the Operator portal.
The procedure is as follows:
The Monitor tab of the selected Controller displays the following details:
You can choose a specific period to view the Controller details for the selected duration at the top of the page.
The page displays a graphical representation of usage details of the following parameters for the period of selected time duration, along with the minimum, maximum, and average values.
| Usage | Description |
|---|---|
| CPU Percentage | Percentage of usage of CPU |
| Memory Usage | Percentage of usage of memory |
| Flow Counts | Count of traffic flow |
| Handoff Queue Drops | Count of packets dropped due to queued handoff |
| Tunnel Count | Count of tunnel sessions |
SD-WAN Gateway Controller Recommended Values to Monitor
The following list shows values that should be monitored and their thresholds. The list below is given as a start point, and it is not exhaustive. Some deployments may require assessing additional components such as flows, packet loss, etc.
Whenever a warning threshold is reached, it is recommended to review the current device scale configuration and add more resources if required. When a critical alarm is triggered, it is crucial to contact Arista Support representatives to check the solution and provide further advice.
| Service Check | Service Check Description | Warn Threshold | Critical Threshold |
|---|---|---|---|
| CPU Load | Check System Load. | 60 | 80 |
| Memory | Checks the memory utilization buffer, cache, and used memory. | 70 | 80 |
| Tunnels | Number of tunnels from connected Edges. | 60% of max Scale | 80% of max Scale
Note: A sudden loss of all tunnels or an abnormal low quantity should also be a concern. |
| Handoff Drops | Due to the busy nature of traffic through a Controller, occasional drops are expected. | Consistent drops in specific queues may indicate a capacity problem. | |
| Disk Space | Current disk utilization | 40% Free | 20% Free |
| Controller NTP | Check for Time offset | Offset of 5 Seconds | Offset of 10 Seconds |
The Orchestrator comes with a built-in system metrics monitoring stack, which can attach to an external metrics collector and a time-series database. With the monitoring stack, you can quickly check the health condition and the system load for the Orchestrator.
Before getting started, set up a time-based database and a dashboard/alerting agent. After this is complete, you can enable Telegraf in Orchestrator.
To enable the monitoring stack, run the following command on the orchestrator: sudo /opt/vc/scripts/vco_observability_manager.sh enable
To check the status of the monitoring stack, run: sudo /opt/vc/scripts/vco_observability_manager.sh status
sudo /opt/vc/scripts/vco_observability_manager.sh disable
The Metrics Collector Telegraf is used as the Orchestrator system metrics collector with plugins to collect different system metrics. The following metrics are enabled by default.
| Metric Name | Description | Supported in Version |
|---|---|---|
| inputs.cpu | Metrics about CPU usage. | 3.4/4.0 |
| inputs.mem | Metrics about memory usage. | 3.4/4.0 |
| inputs.net | Metrics about network interfaces. | 4.0 |
| inputs.system | Metrics about system load and uptime. | 4.0 |
| inputs.processes | The number of processes grouped by status. | 4.0 |
| inputs.disk | Metrics about disk usage. | 4.0 |
| inputs.diskio | Metrics about disk IO by device. | 4.0 |
| inputs.procstat | CPU and memory usage for specific processes. | 4.0 |
| inputs.nginx | Nginx's basic status information (ngx_http_stub_status_module). | 4.0 |
| inputs.mysql | Statistic data from MySQL server. | 3.4/4.0 |
| inputs.redis | Metrics from one or many redis servers. | 3.4/4.0 |
| inputs.statds | API and system metrics. | 3.4/4.0 (additional metrics are included in 4.0) |
| inputs.filecount | The number and the total size of files in specified directories. | 4.0 |
| inputs.ntpq | Standard NTP query metrics, requires ntpq executable. | 4.0 |
| Inputs.x509_cert | Metrics from a SSL certificate. | 4.0 |
To activate more metrics or deactivate some enabled metrics, you can edit the Telegraf configuration file on the Orchestrator using the following commands:
sudo vi /etc/telegraf/telegraf.d/system_metrics_input.confsudo systemctl restart telegraf
Follow the instructions below to setup the time-series database.
iptables entry updated.

/etc/telegraf/telegraf.d/prometheus_out.conf
The following list shows a list of values that should be monitored and their thresholds. The list below is given as a starting point, as it is not exhaustive. Some deployments may require assessing additional components such as database transactions, automatic backups, etc.
| Service Check | Service Check Description | Warn Threshold | Critical Threshold |
|---|---|---|---|
| CPU Load | Check System Load – Telegraf input plugin: inputs.cpu. | 60 | 70 |
| Memory | Checks the memory utilization buffer, cache, and used memory – Telegraf input plugin: inputs.memory. | 70 | 80 |
| Disk Usage | Disk Utilization in the different Orchestrator partitions, /, /store, /store2 and /store3 (version 4.0 and onwards) – Telegraf input plugin: inputs.disk (version 4.0 and onwards). | 40% Free | 20% Free |
| MySQL Server | Checks MySQL Connections-Telegraf input plugin: inputs.mysql. | Above 80% of max connection define in mysql.conf(/etc/mysql/my.cnf) | |
| Orchestrator Time | Check for Time offset-Telegraf input plugin: inputs.ntpq (version 4.0 and onwards). | Offset of 5 Seconds | Offset of 10 Seconds |
| Orchestrator SSL Certificate | Checks Certificate Expiration- Telegraf input plugin: inputs.x509_cert (version 4.0 and onwards). | 60 Days | 30 Days |
| Orchestrator Internet (not applicable for MPLS only topologies) | Check for Internet access. | Response time > 5 secs | Response time > 10 secs |
| Orchestrator HTTP | Make sure HTTP on localhost is responding. | The localhost is not responding. | |
| Orchestrator Total Cert Count | Check Total – Example mysql query:
SELECT count(id) FROM VELOCLOUD_EDGE_CERTIFICATE WHERE validFrom <= NOW() AND validTo >=NOW()', 'SELECT count(id) FROM VELOCLOUD_GATEWAY_CERTIFICATE WHERE validFrom <= NOW() AND validTo >=NOW() |
CRL | When Total Cert count exceeds 5000 |
| DR Replication Status | Confirm the Standby Orchestrator is up-to-date. | Review that the DR Orchestrator is no more than 1000 seconds behind the Active Orchestrator.
Seconds_Behind_Master: from mysql command: show slave STATUS\G; |
|
| DR Replication Edge Gateway delta | Confirm that Edges and Gateways can talk to the DR Orchestrator.
Different values between the Active and the Standby Orchestrators can be due to a difference in the timezone in Edges and Gateways. |
The same amount of Edges talking with the Active Orchestrator should be able to reach the Standby Orchestrator. This value can be checked on the "replication" tab or via the API. | |
Orchestrator powers the management plane in the VeloCloud SD-WAN solution. It offers a broad range of configuration, monitoring, and troubleshooting functionality to service providers and enterprises. The main web service with which users interact to exercise this functionality is called the Orchestrator Portal.
Orchestrator Portal- The Orchestrator Portal allows network administrators (or scripts and applications acting on their behalf) to manage network and device configuration and query the current or historical network and device state. API clients may interact with the Portal via a JSON-RPC interface or a REST-like interface. It is possible to invoke all of the methods described in this document using either interface. There is no Portal functionality for which access is constrained exclusively to either JSON-RPC clients or REST-like ones.
Both interfaces accept exclusively HTTP POST requests. Both also expect that request bodies, contain JSON-formatted content consistent with RFC 2616. Clients are furthermore likely to formally assert where this is the case using the Content-Type request header, e.g., Content-Type: application/json.
More information about the VeloCloud SD-WAN API can be found here:
https://code.Arista.com/apis/1000/velocloud-sdwan-vco-api
monitoring/getAggregateEdgeLinkMetrics may be used to retrieve transport stats across all Edges concurrently.This log is very useful for AAA activities as it has all actions taken by users in the Orchestrator.
Log files: /var/log/portal/velocloud.log (Logs all info, warn, and error logs)
Log files: /var/log/upload/velocloud.log (Logs all info, warn, and error logs)
Log files: /var/log/backend/velocloud.log (Logs all info, warn, and error logs)
Use the following steps to configure Orchestrator Syslog:
enable:false value to true for one or more of the servers. Change the Host IP and port accordingly to your implementation.

For detailed instructions to increase the Storage in the Orchestrator, see the topics Install SD-WAN Orchestrator and Expand Disk Size (Arista).
The following guidelines in the table below should be used in the 4.x release and onwards.
| Instance Size | /store | /store2 | /store3 | /var/log |
|---|---|---|---|---|
| Small (5000 Edges) | 2 TB | 500 GB | 8 TB | 100 GB |
| Medium (10000 Edges) | 2 TB | 500 GB | 12 TB | 125 GB |
| Large (15000 Edges) | 2 TB | 500 GB | 16 TB | `150 GB |
Orchestrator uses a built-in certificate server to manage the overall PKI lifecycle of all Edges and SD-WAN Controllers. X.509 certificates are issued to the devices in the network.
Detailed instructions to configure the CA can be found in the official VeloWare SD-WAN Operator documentation, under Install Orchestrator and Install an SSL Certificate.
Certificate Revocation List
On Controllers with PKI enabled, revoked certificates are stored in a Certificate Revocation List (CRL). If this list grows too long, generally due to an issue with the Orchestrator Certificate Authority, the Controller's performance becomes impacted. The CRL should be less than 4,000 entries long.
vcadmin@vcg1-example:~$ openssl crl -in /etc/vc-public/vco-ca-crl.pem -text | grep 'Serial Number' | wc -l 14 vcadmin@vcg1-example:~Our Customer Support organization provides 24x7x365 world-class technical assistance and personalized guidance to VeloCloud SD-WAN customers.
While investigating an incident, a diagnostic bundle of the Orchestrator and SD-WAN Controller can be created. The resulting file will assist the Arista Support team to further analyze the events around an issue.


On occasion assistance from Arista Support representatives for the Orchestrator and SD-WAN Controllers may be required.
When contacting Arista SD-WAN Support to assist triaging an issue, include the data described in the table below.
Additional information can be found in the following link: https://www.arista.com/en/support/customer-support/velocloud.
| Required | Suggested |
|---|---|
| Partner Case Number | Issue Start/Stop |
| Partner Return Email/Phone | Impacted Flow SRC/DST IP |
| Orchestrator URL | Impacted Flow SRC/DST Port |
| Customer Name in Orchestrator | Flow Path (E2E, E2GW, Direct) |
| Customer Impact (High/Med/Low) | SD-WAN Gateway Name(s) |
| Edge Name(s) | Link to PCAP in the Orchestrator |
| Link to Diagnostic Bundle in Orchestrator | |
| Short Problem Statement | |
| Analysis & Requested Assistance |
www.arista.com
Version 6.4
DOC-08150-03
|
Headquarters
5453 Great America Parkway
Santa Clara, CA 95054, USA +1-408 547-5500 www.arista.com
|
Support
+1-408 547-5502
+1-866 476-0000 This email address is being protected from spambots. You need JavaScript enabled to view it.
|
Sales
+1-408 547-5501
+1-866 497-0000 This email address is being protected from spambots. You need JavaScript enabled to view it.
|